

There are countless articles about HTTP online, so this series will not merely list concepts. Instead, we will explore various details of the HTTP protocol through practical examples (packet capture + code implementation) to help you grasp those hard-to-remember concepts. We will also focus on implementing these examples with a Netty server.
We will use Netty to build a server and use HttpClient to implement an HTTP client.
❝Those unfamiliar with Netty or HttpClient need not worry, as the code involved is very simple. The reason I chose these two frameworks for the server side is because they provide relatively shallow encapsulation of the HTTP protocol, which will allow us to explore how the HTTP protocol is packaged at the code level in later articles. This way, you can gain a deeper understanding of the HTTP protocol. In this article, focus on the packet capture and analysis process!❞
The code is as follows:
Dependency introduction in the pom file:
Server-side code:
Client-side code is as follows:
We will start the server, run the client, and when it outputs “Hello World” successfully, it indicates the project is set up correctly.
Wireshark (formerly known as Ethereal) is a network packet analysis tool. It is mainly used to capture network data packets and automatically analyze them, displaying detailed information about the packets for user analysis.
❝Download link: https://www.wireshark.org/download.html❞
After a successful download, we see the main interface as follows:
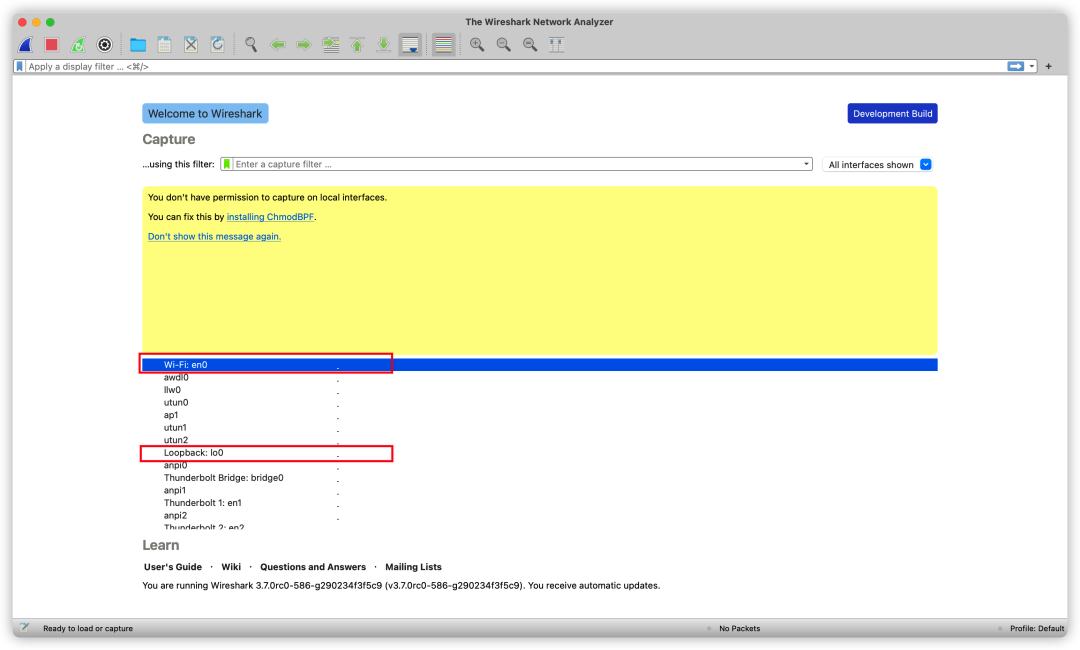
WireShark
The list shown here is our machine’s network card list. We need to confirm the specific network card before capturing packets, typically the ones I outlined in the picture.
How do we determine which network card the packets we want to capture correspond to?
Now, to determine which network card is used when we access the web, we can perform the following:
From here, you can see the IP address used when accessing Baidu (mosaic part in the picture).
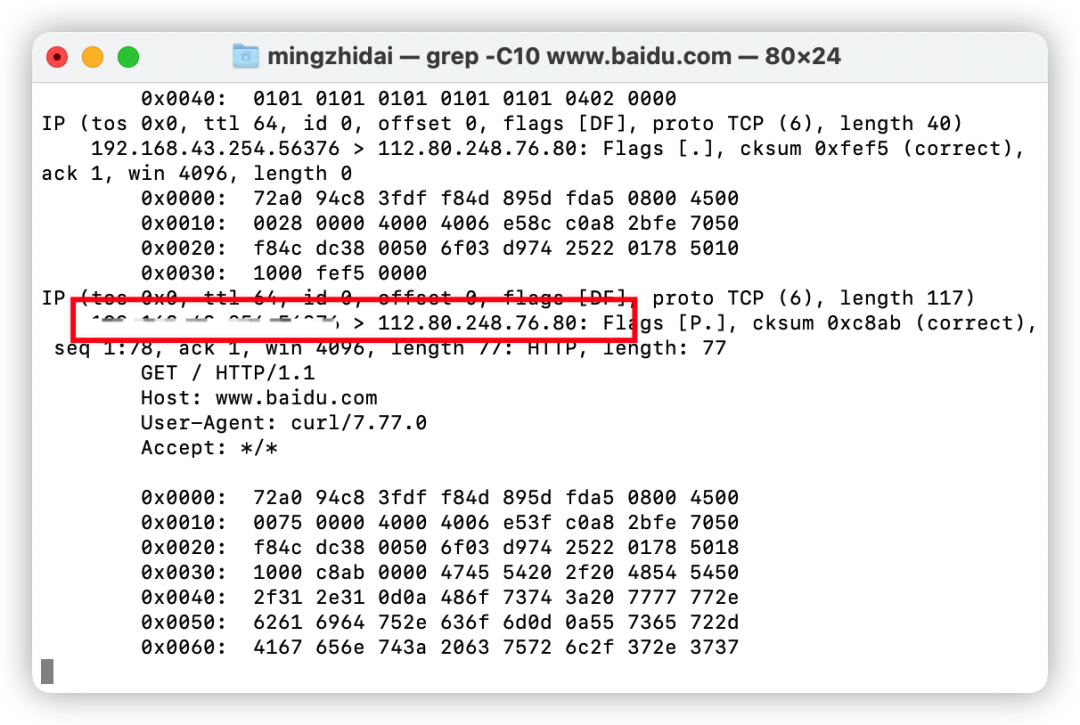
Then, by executing a command, you can query which network card corresponds to this IP.
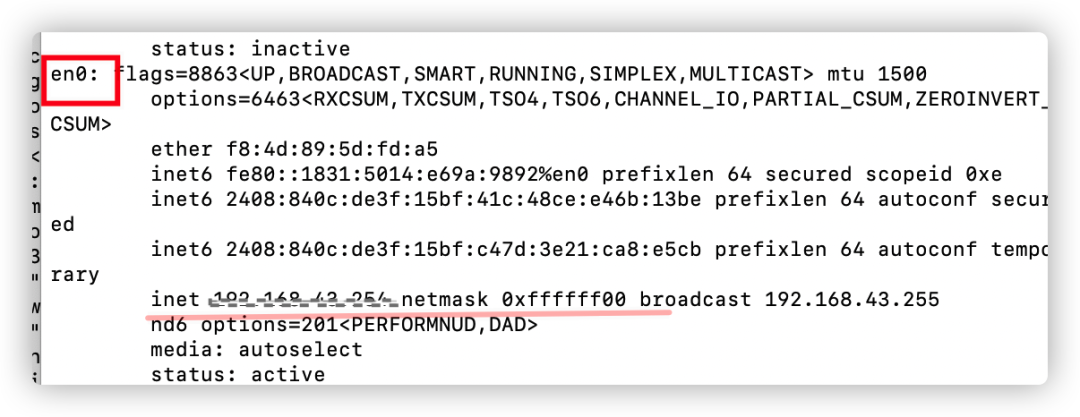
On my machine, it corresponds to the en0 network card. Once the specific network card is confirmed, we select it in the main interface and double-click. At this time, the following error may appear:
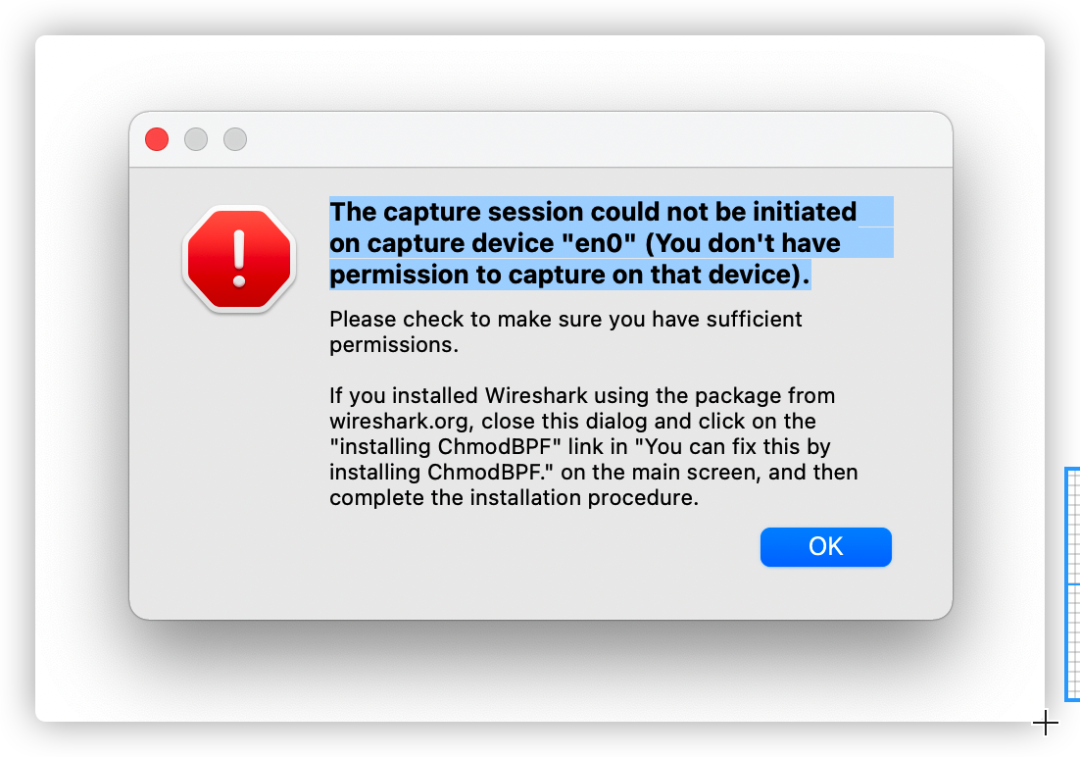
This is due to network card permission issues, and we only need to enter the following command in the terminal. Remember to restart WireShark after execution.
Once restarted, double-click on the selected network card and enter the following interface:
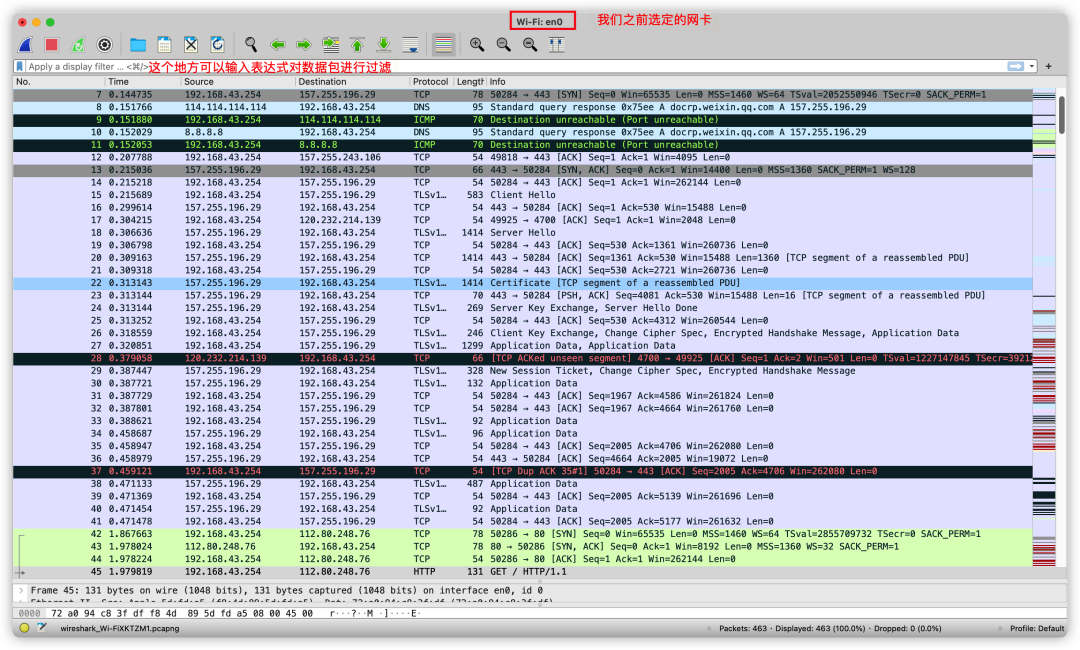
Initially, entering this interface might be confusing as we haven’t entered any filter expression; hence, the entire interface shows all packets on the en0 network card. The expressions for WireShark are not the focus here, and I don’t intend to introduce them extensively. The expressions used in this article are simple, and I will provide brief explanations for each.
At this point, to capture packets when accessing Baidu, input the following expression:
The first line of the expression represents that we want to capture packets related to the HTTP protocol. Similarly, you can input protocol names like TCP, ICMP, etc., to filter related packets. This expression means we want to capture packets related to the HTTP protocol and one party’s IP address is, which can be obtained through.
Based on the above expression, we can capture packets as follows:
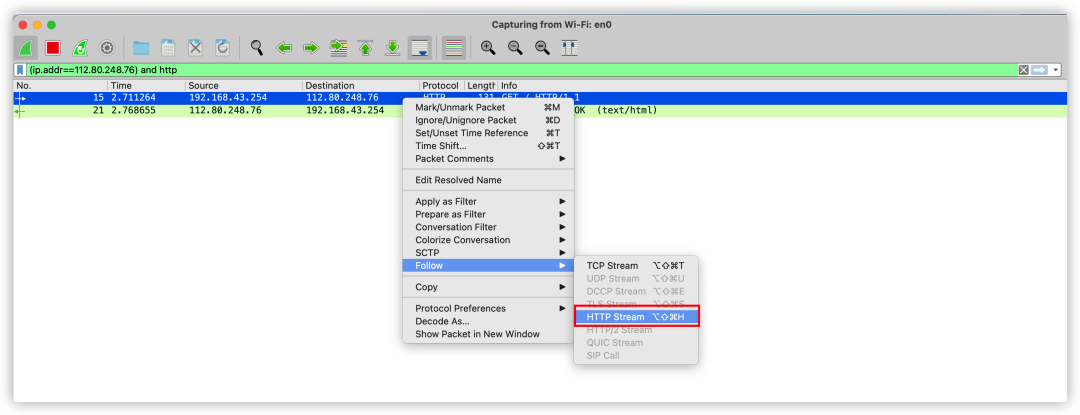
Select the corresponding message, right-click to track the HTTP stream, and you can obtain specific HTTP message information.

Now let’s officially start the packet capture experiment, ensuring your test project and Wireshark are both okay~
Next, start the server side, and then run the client side to initiate an HTTP request, capturing the following data on WireShark:

As mentioned earlier, by tracking this HTTP stream, the following data can be seen:
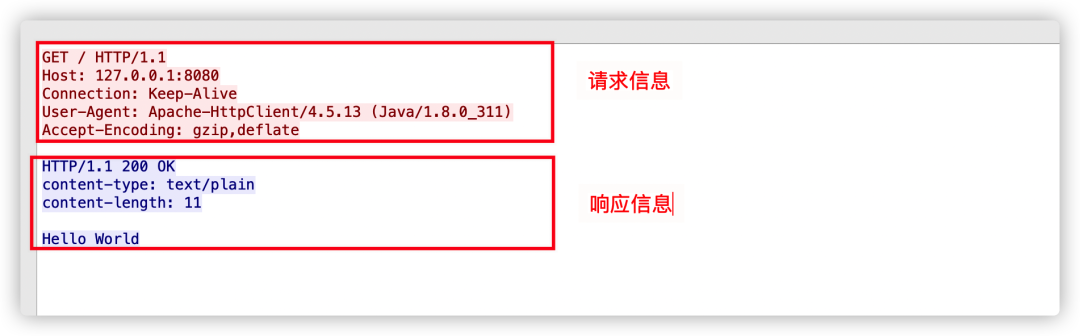
The structure of HTTP protocol request and response messages is basically the same, composed of three main parts:
(start line): Describes the basic information of the request or response; in requests, it is called the request line, and in responses, the status line;
(header): Provides more detailed explanation of the message using the key-value format; in requests, it’s called the request header, and in responses, the response header;
(entity): The actual transmitted data, which may not just be plain text but could be images, videos, or other binary data, also known as the request body or response body.
The HTTP protocol requires that the message must have a header, but it may not have a body. Also, there must be an “empty line” after the header, which is “CRLF”, hexadecimal “0D0A”.
The packets obtained from the capture can be described using the above structure, as shown in the image below:
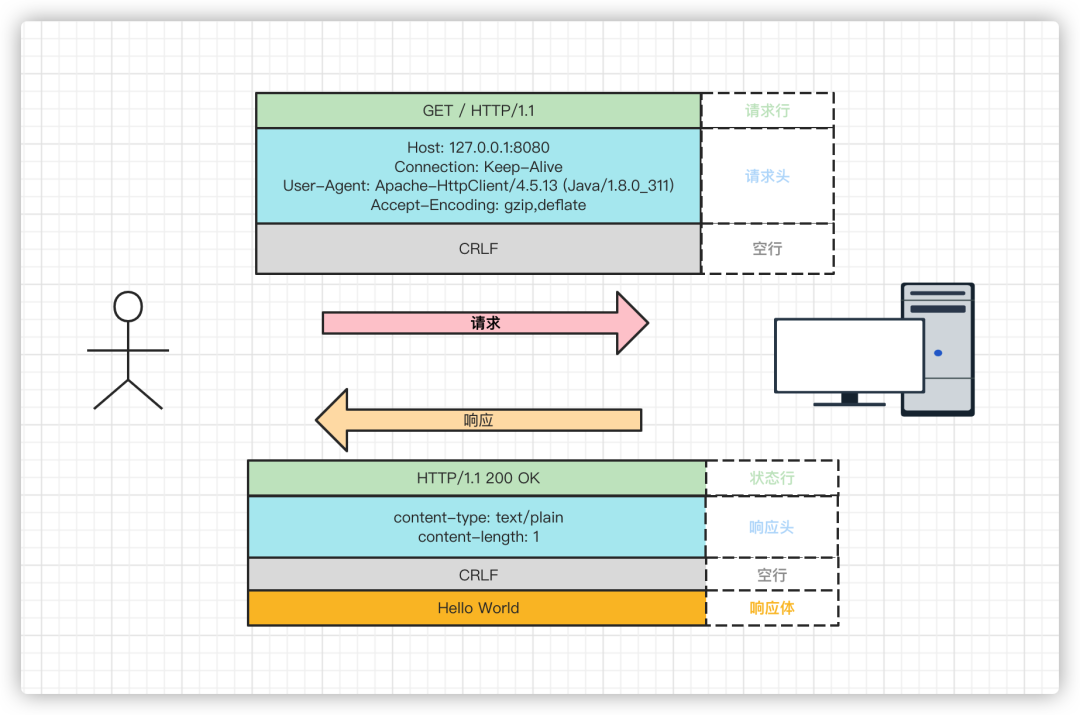
As shown in the image below, the request line mainly contains three parts of information.
The three parts are separated by spaces.
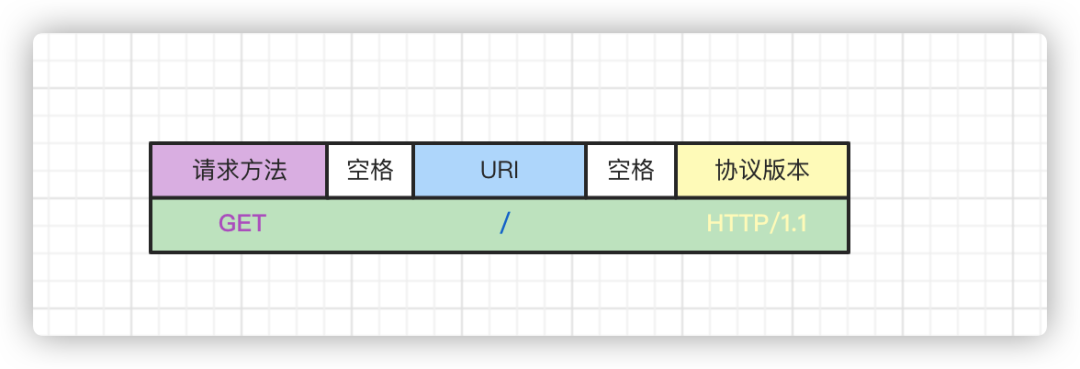
| Request Method | Description | Additional Info |
|---|---|---|
| GET | Requests to obtain resources from the server | This resource can be a static text, page, image, video, or a page dynamically generated by PHP, Java, or other formats of data |
| POST | Submits data to the server (e.g., submitting forms or uploading files), data is contained in the request body | POST signifies “create” |
| PUT | The purpose of PUT is similar to POST, data is also included in the request body | Usually, POST indicates “create,” while PUT is “update.” |
| DELETE | Instructs the server to delete resources | Used more often in RESTful architecture |
| HEAD | Similar to the GET request, but the response doesn’t contain the content, used to get headers | HEAD can be seen as a “simplified version” or “lightweight version” of GET. Its response header is identical to GET, so it can be used where resources are not truly needed, avoiding body data transfer waste. |
| OPTIONS | This method requests the server to list the operations applicable to resources in the Allow field of the response header | It is very limited in function and not of much use. Some servers (e.g., Nginx) don’t support it at all. |
| TRACE | Used for testing or diagnosing the HTTP link, showing the request-response path. | While it was intended positively, it has vulnerabilities that leak website information, so web servers usually disallow its use. |
| CONNECT | Requests a connection with a proxy through the tunnel protocol | For information on tunnels, see: https://www.zhihu.com/question/21955083; this article won’t elaborate further. |
❝Under RESTful architecture, four verbs are used to denote operations: GET, POST, PUT, DELETE. They each correspond to four basic operations:❞

As shown in the image below, the request line mainly contains three parts of information.
The three parts are separated by spaces.

The RFC standard categorizes status codes into five categories, represented by the first digit of the code, significantly reducing the usable range from 000~999 to 100~599.
The specific meanings of these five categories are:
1××: Informational, indicating that the request has been received and understood, and the process is continuing; further action may be needed from the client
2××: Success, indicating that the request was successfully received, understood, and accepted;
3××: Redirection, indicating that further action needs to be taken to complete the request; the client should use the new URL;
4××: Client Error, indicating that the client seems to have made a mistake with the request;
5××: Server Error, indicating that the server failed to fulfill a valid request.
❝It is important to note that HTTP itself is a protocol, requiring both parties to comply, but it is not mandatory. Currently, the RFC standard has a total of 41 status codes, but the definition of status codes is open, allowing for self-extension. Therefore, Apache, Nginx, and other web servers define certain proprietary status codes. If you develop a web application, you can also define new status codes as long as they don’t conflict.❞
The class status code signals a kind of “intermediate” state in protocol processing. For example, when protocol upgrades are required, the server would respond with 101. As shown in the image below, when using WebSocket, a protocol upgrade takes place:
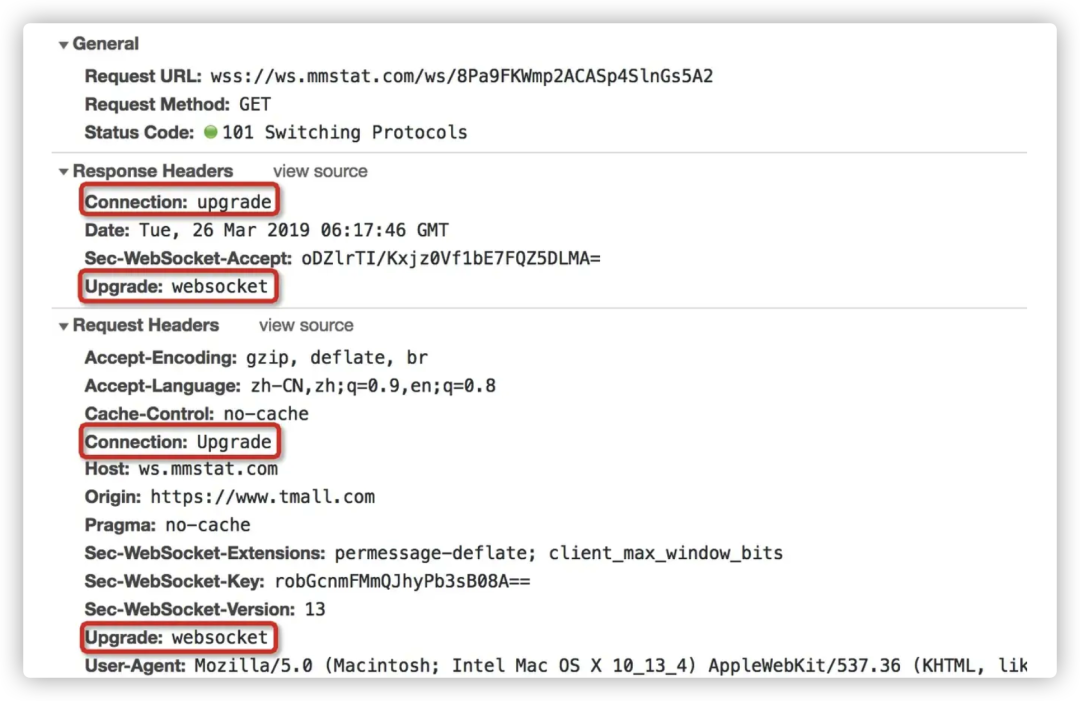
A class status code indicates that the server successfully processed the client’s request, which is the most favorable outcome you can see.
The class status code means the requested resource has been moved, requiring the client to fetch it again with the new URL, in other words.
301 and 302 will specify the new URL in the response header, and the browser will automatically redirect to the new URL.
4×× class status code signifies that the client’s request message contains errors, and the server can’t process it, representing a real “error code.”
“400 Bad Request” is a common error code, suggesting the request message contains errors, but doesn’t explicitly indicate whether it’s data format errors, missing request headers, or excessively long URLs. It’s just a general error, causing the client to be “confused” and “at a loss.” Therefore, when developing web applications, you should avoid returning 400 to the client and instead, use other status codes with clearer meanings.
“403 Forbidden” doesn’t actually mean an error in the client’s request, it simply signals that the server is prohibiting access to the resource. The reasons could vary, such as sensitive information, legal prohibitions, etc. If the server is a bit nicer, it might detail the reason for refusing the request in the body, but in reality, it mostly offers a “closed-door” response.
“404 Not Found” might be the most frequently encountered and dreaded status code. Originally, it meant that the resource wasn’t found on the server, so it could not be supplied to the client. However, it’s now overused, and any server “in a bad mood” might throw a 404 at you without revealing the real reason behind it, making it even more annoying than 403.
The remaining codes in the 4×× class provide clearer explanations of the cause of the error and are generally well-understood in development, commonly used ones include:
The class status code implies that the client’s request message is correct but falls under server-side error code.
The HTTP header message is usually divided into four parts: general header, request header, response header, entity header. But this division feels rather unclear. Based on how Wikipedia organizes the content of the HTTP header, it can be broadly divided into the Request (request header) and Response (response header).
| Header | Explanation | Example |
|---|---|---|
| Accept | Specifies the content types the client can receive | Accept: text/plain, text/html |
| Accept-Charset | The character encoding set the client can accept. | Accept-Charset: iso-8859-5 |
| Accept-Encoding | Specifies the compression encoding types supported by the client for the web server’s returning content. | Accept-Encoding: compress, gzip |
| Accept-Language | The language acceptable to the client | Accept-Language: en, zh |
| Accept-Ranges | Indicates if partial requests for the resource are supported, and what types of sub-range requests are allowed | Accept-Ranges: bytes |
| Authorization | Authorization credential for HTTP | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | Specifies caching mechanisms followed for the request and response | Cache-Control: no-cache |
| Connection | Indicates if a persistent connection is required (HTTP 1.1 defaults to a persistent connection) | Connection: close |
| Cookie | When an HTTP request is sent, it transmits all cookie values saved under the requesting domain name to the web server. | Cookie: $Version=1; Skin=new; |
| Content-Length | The length of the request content | Content-Length: 348 |
| Content-Type | The MIME information corresponding to the request entity | Content-Type: application/x-www-form-urlencoded |
| Date | The date and time when the request was sent | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | Particular server behavior expected from the request | Expect: 100-continue |
| From | The email of the user making the request | From: [email protected] |
| Host | Specifies the domain name and port number of the server requested | Host: www.zcmhi.com |
| If-Match | The request is effective only if the content matches the entity | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | The request succeeds only if the requested part has been modified since the specified time; if not modified, returns a 304 status code | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | If content is unchanged then returns a 304 status code; the parameter is the Etag previously sent by the server, compared against the server’s response Etag to judge the change | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | If the entity is unchanged, the server sends the missing portion, otherwise, it sends the entire entity; the parameter is also the Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | The request succeeds only if the entity has not been modified since the specified time | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | Limits the time information transmitted through a proxy or gateway | Max-Forwards: 10 |
| Pragma | Used to include specific instructions | Pragma: no-cache |
| Proxy-Authorization | Authorization credential for connecting to the proxy | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | Requests only a portion of an entity, specifying the range | Range: bytes=500-999 |
| Referer | The address of the previous webpage, the current requested webpage follows it, i.e., the source | Referer: http://www.zcmhi.com/archives/71.html |
| TE | Transmission encoding the client is willing to accept, and it notifies the server to accept tailing header information | TE: trailers,deflate;q=0.5 |
| Upgrade | Specifies the transmission protocol for the server to switch, if supported | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | The contents of User-Agent contain the user’s information making the request | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | Notifies the gateway or proxy server address and communication protocol | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | Warning information about message entities | Warn: 199 Miscellaneous warning |
| Header | Explanation | Example |
|---|---|---|
| Accept-Ranges | Indicates whether the server supports partial requests for resources, and what kind of segmented requests | Accept-Ranges: bytes |
| Age | The estimated time (in seconds, non-negative) from the original server to the proxy cache | Age: 12 |
| Allow | Indicates the valid request behaviors for a network resource, if not allowed returns 405 | Allow: GET, HEAD |
| Cache-Control | Tells all caching mechanisms whether they may cache, and which type | Cache-Control: no-cache |
| Content-Encoding | Compress encoding types supported by the web server to return content. | Content-Encoding: gzip |
| Content-Language | The language of the response body | Content-Language: en, zh |
| Content-Length | Length of the response body | Content-Length: 348 |
| Content-Location | An alternative address for the requested resource | Content-Location: /index.htm |
| Content-MD5 | The MD5 checksum of the returned resource | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | The byte position of this part in the entire return body | Content-Range: bytes 21010-47021/47022 |
| Content-Type | The MIME type of the return content | Content-Type: text/html; charset=utf-8 |
| Date | The date and time the message was sent from the original server | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag | The current value of the entity tag of the requested variable | ETag: “737060cd8c284d8af7ad3082f209582d” |
| Expires | The expiration date and time of the response | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | The last modification time of the requested resource | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location | Used to redirect the recipient to a location other than the requested URL to complete the request or to identify a new resource | Location: http://www.zcmhi.com/archives/94.html |
| Pragma | Includes specific instructions that apply to any recipient in the response chain | Pragma: no-cache |
| Proxy-Authenticate | Indicates the authentication scheme and applicable URL parameters on the proxy | Proxy-Authenticate: Basic |
| refresh | Applied to redirection or when a new resource is created, redirect after 5 seconds (proposed by Netscape, supported by most browsers) | Refresh: 5; url=http://www.zcmhi.com/archives/94.html |
| Retry-After | Notifies the client to try again after the specified time if the entity is temporarily unavailable | Retry-After: 120 |
| Server | Name of the web server software | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie | Sets the Http Cookie | Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Trailer | Indicates header domains are present at the end of a chunked transfer encoding | Trailer: Max-Forwards |
| Transfer-Encoding | File transfer encoding | Transfer-Encoding:chunked |
| Vary | Tells downstream proxies whether to use a cached response or request a fresh one from the original server | Vary: * |
| Via | Informs the proxy client of the response’s route | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | Warning about possible issues with entities | Warning: 199 Miscellaneous warning |
| WWW-Authenticate | Indicates the authorization scheme the client should use for the request entity | WWW-Authenticate: Basic |
Through this article, we set up the test project, gained a basic understanding of WireShark, and learned about the overall structure of the HTTP protocol. However, with this limited understanding, it’s challenging to have an intuitive, in-depth grasp of HTTP. So, in the next article, I will discuss with you how mainstream frameworks implement the HTTP protocol, such as how HTTP’s persistent connections are realized at the code level, and what the server and client do to achieve persistent connections.
The next article will analyze the HTTP protocol from a code implementation perspective, follow me, and let’s dive in~“`