

Introduction
Content-Length, the HTTP message length, is represented by the number of bytes in decimal digits. In general, many tasks are handled by frameworks, so we rarely pay attention to this content, but in rare cases where Content-Length doesn’t match the actual message length, the program may experience rather strange anomalies, such as:
- No response until timeout.
- The request gets truncated, and the parsing of the next request becomes confused.
What is Content-Length
Content-Length is the length of the HTTP message, represented by the number of bytes in decimal digits, and is a common field in Headers. Content-Length should be precise, otherwise it will lead to anomalies (specifically, in HTTP1.0, this field is optional).
The Content-Length header indicates the byte size of the entity body in the message. This size includes all content encoding, for example, if a text file is compressed with gzip, the Content-Length header refers to the size after compression and not the original size.
How Content-Length Works
Content-Length uses decimal numbers to represent the message’s length, allowing the server/client to know the length of the message to be read next.
 >
>
If this length is incorrect, the following situations occur:
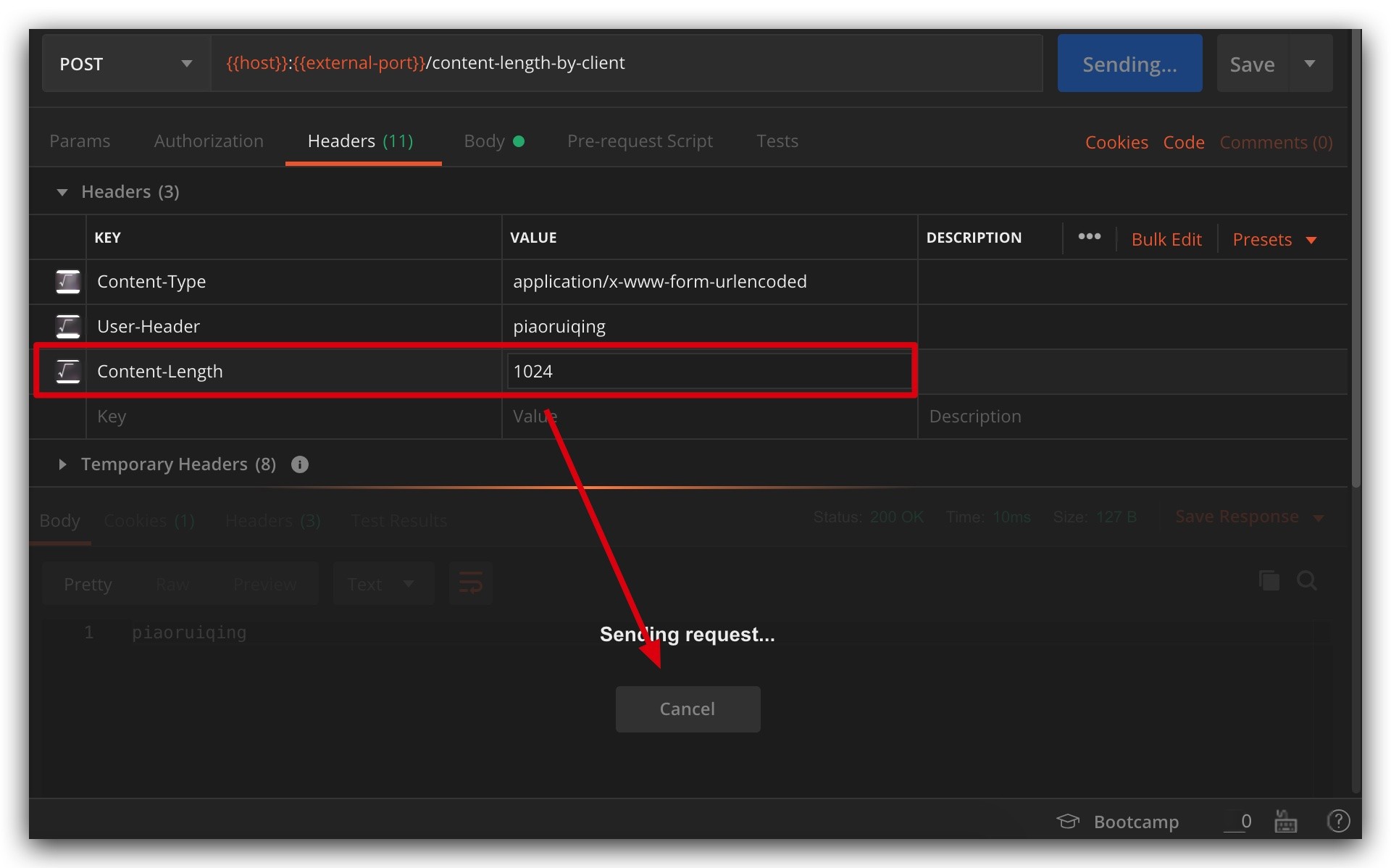
Content-Length > Actual Length
If the Content-Length is larger than the actual length, after reading to the end of the message, the server/client will wait for the next byte, naturally leading to no response until timeout.
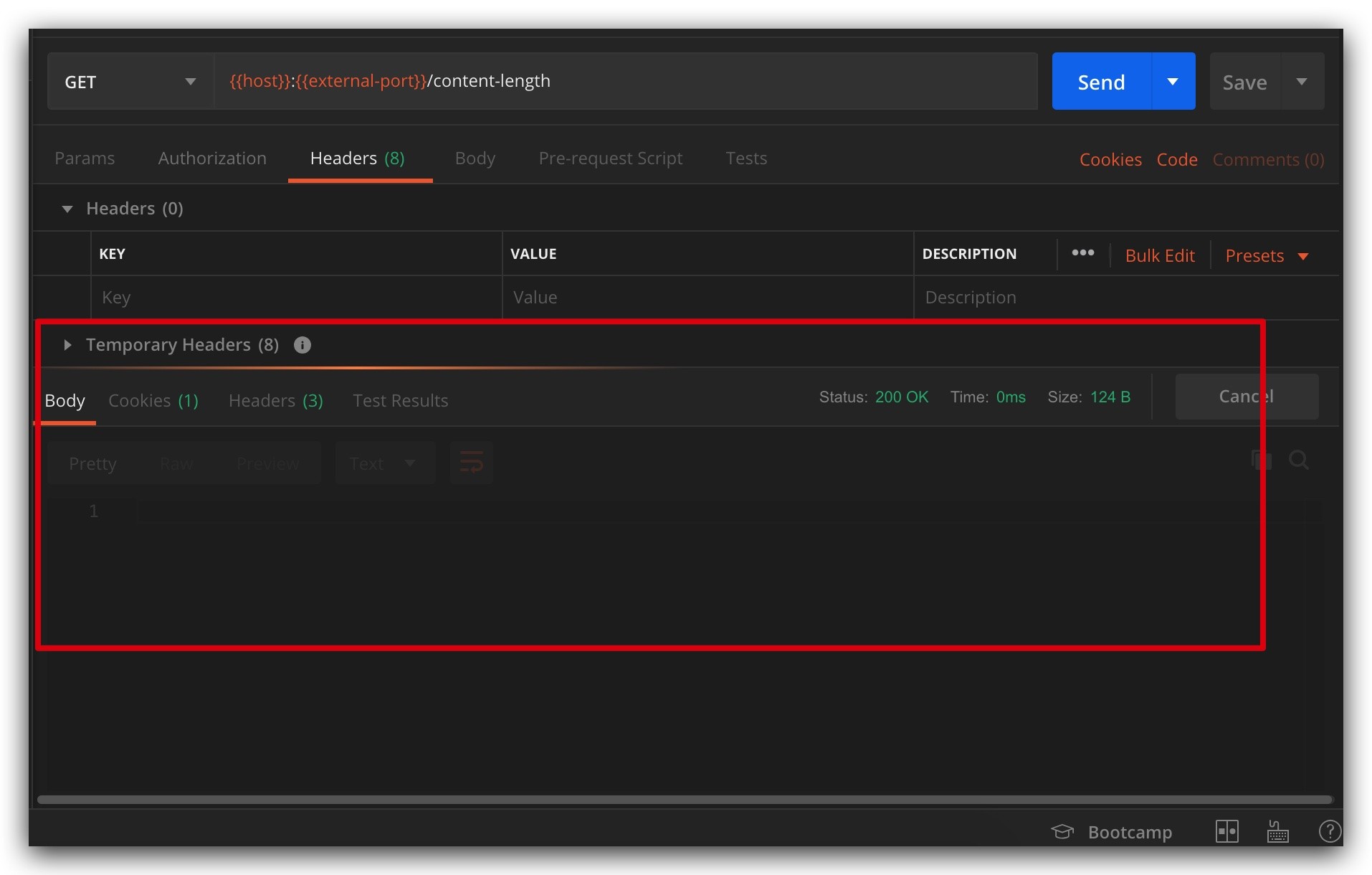
Similarly, if the Content-Length in the response message exceeds the actual length, the effect is the same:

Content-Length < Actual Length
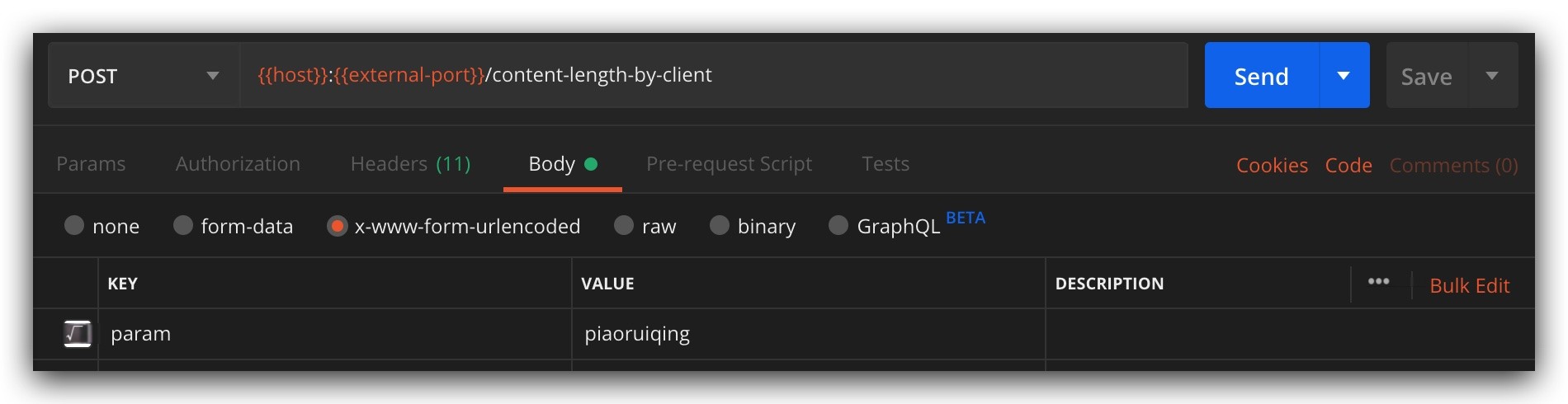
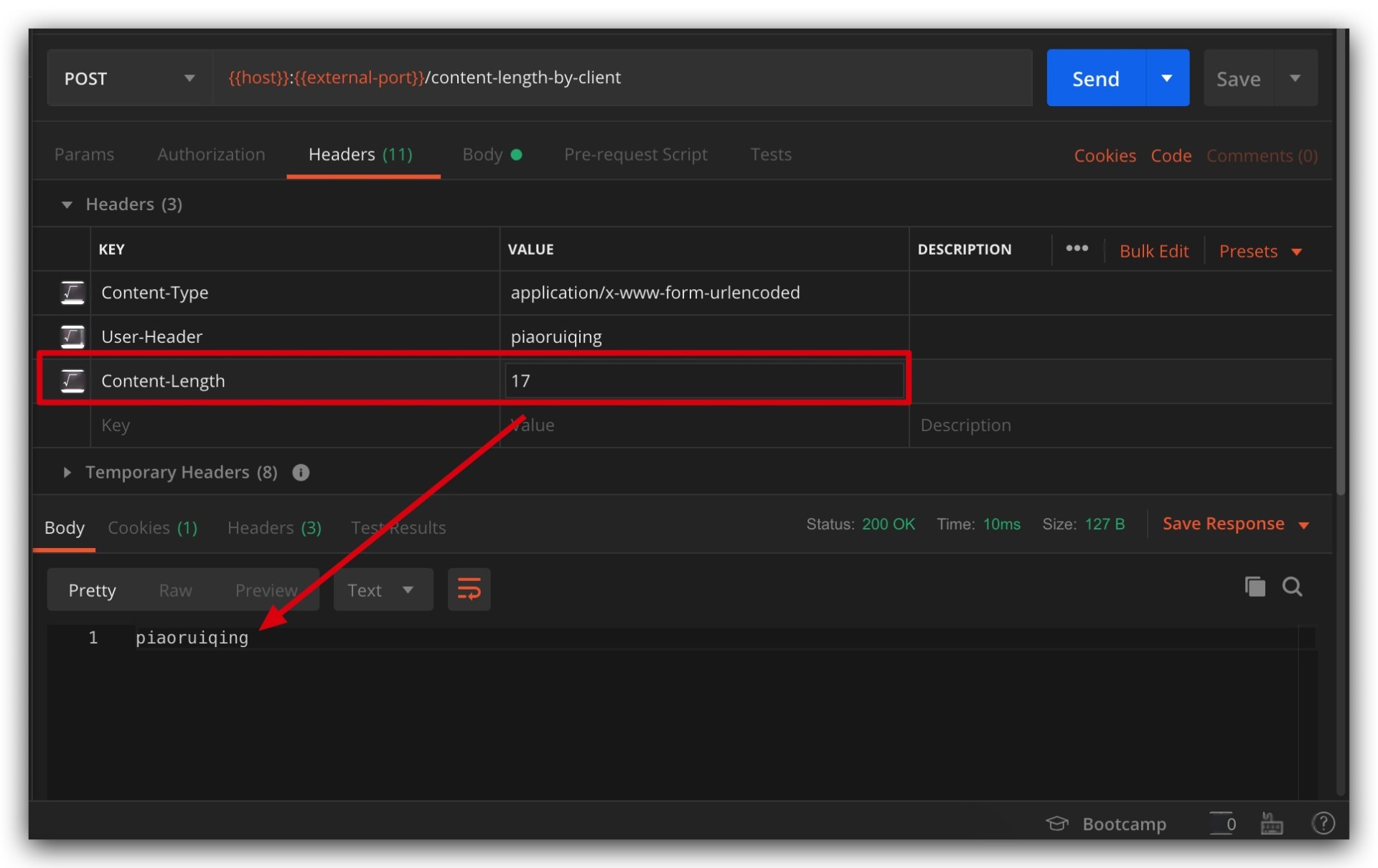
If this length is less than the actual length, the first request’s message will be truncated, for example, the parameter is param=piaoruiqing, and Content-Length is 10, then the message of this request will be truncated to: param=piao, as shown:
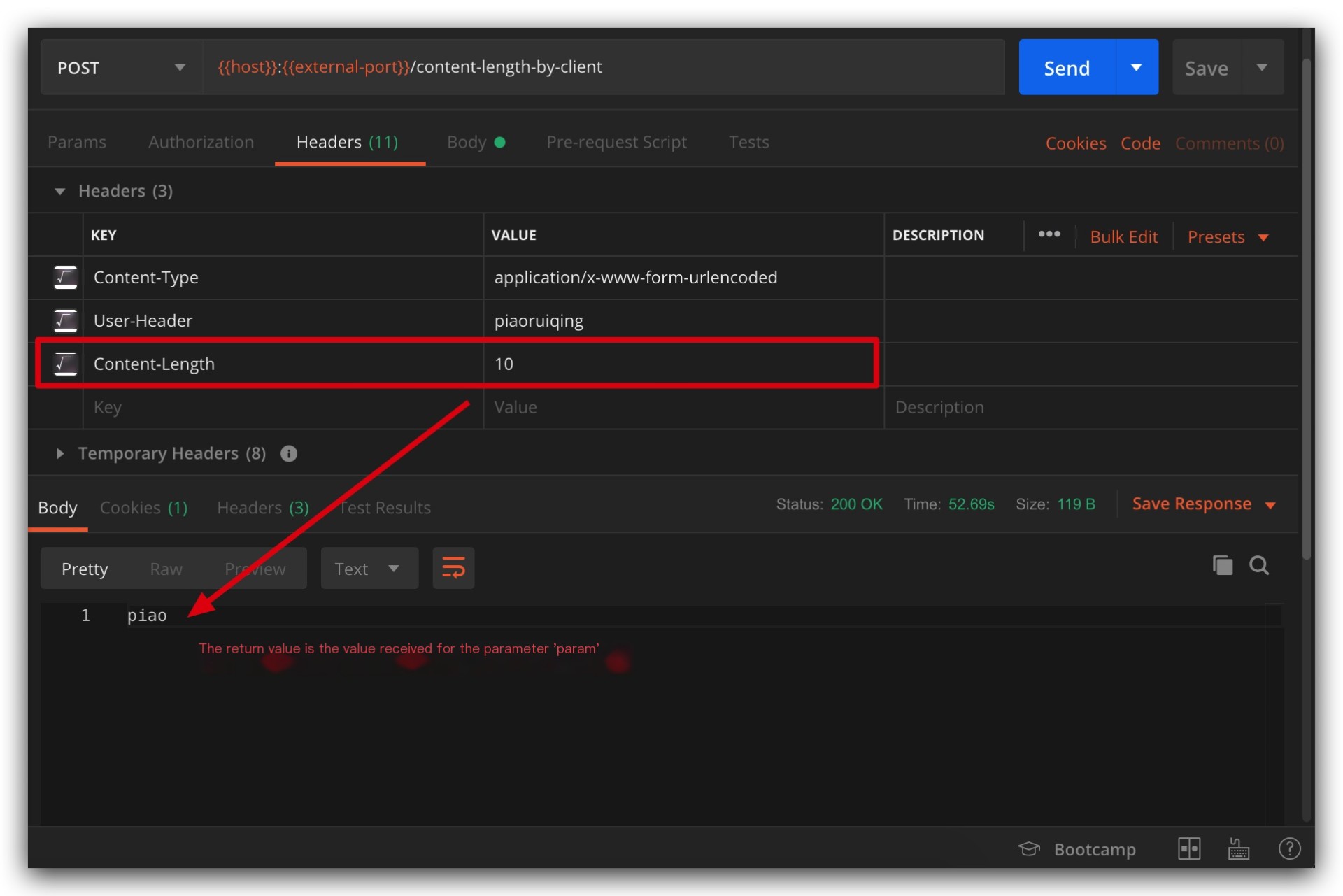

But, is that it? Of course not, let’s see what unexpected things occur during the second request, as shown:
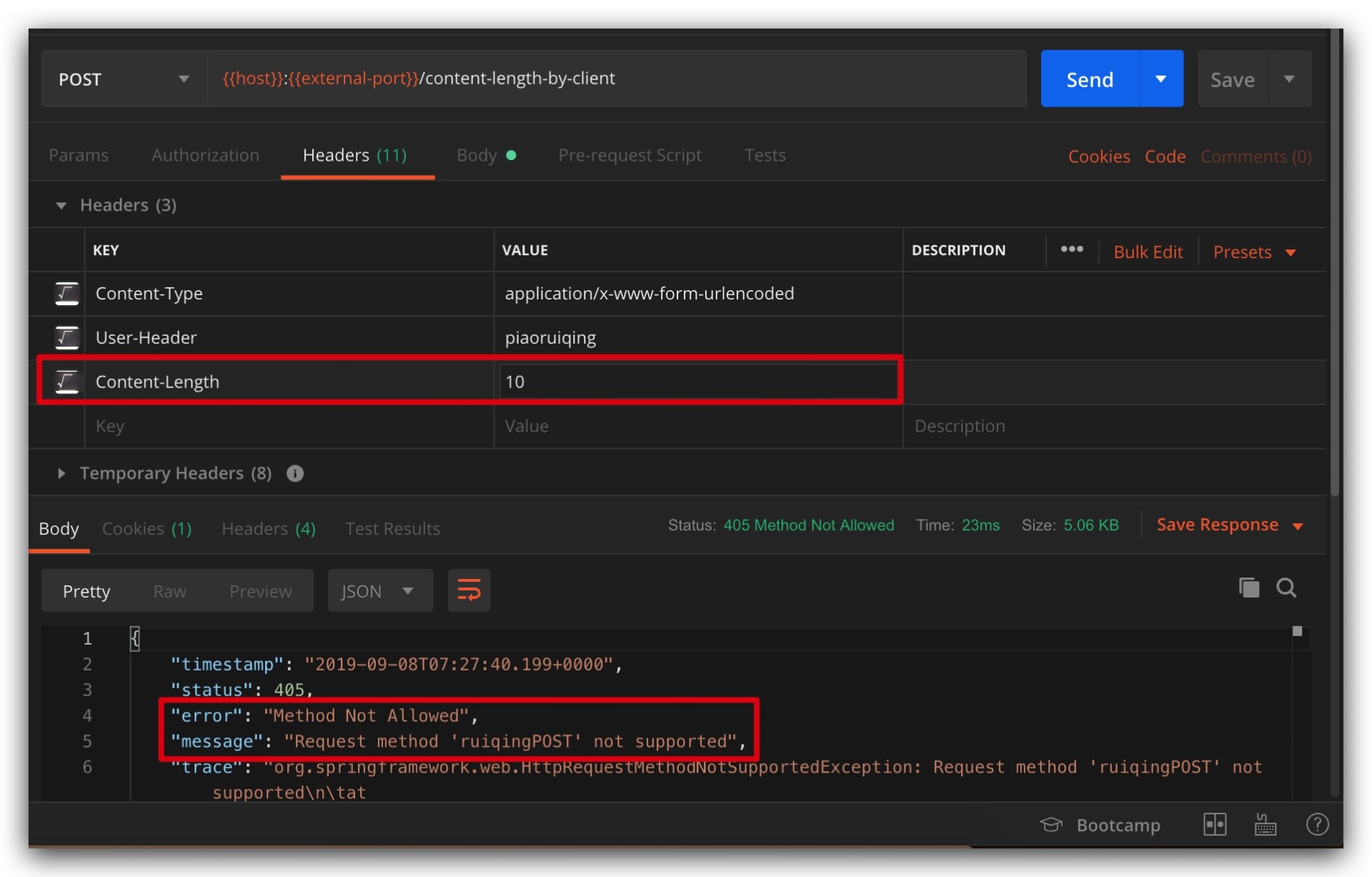
During two consecutive requests, the first message is truncated, while the second doesn’t experience the expected cutoff, instead the server throws an exception: Request method 'ruiqingPOST' not supported. Isn’t it exciting? (ノ)゚Д゚( )
What kind of magical method is ruiqingPOST? At this point, with the sensitivity cultivated through years of development (DEBUG) experience, we can generally guess that the leftover message from the previous request appeared in this request. Whip out Wireshark to verify, as shown:
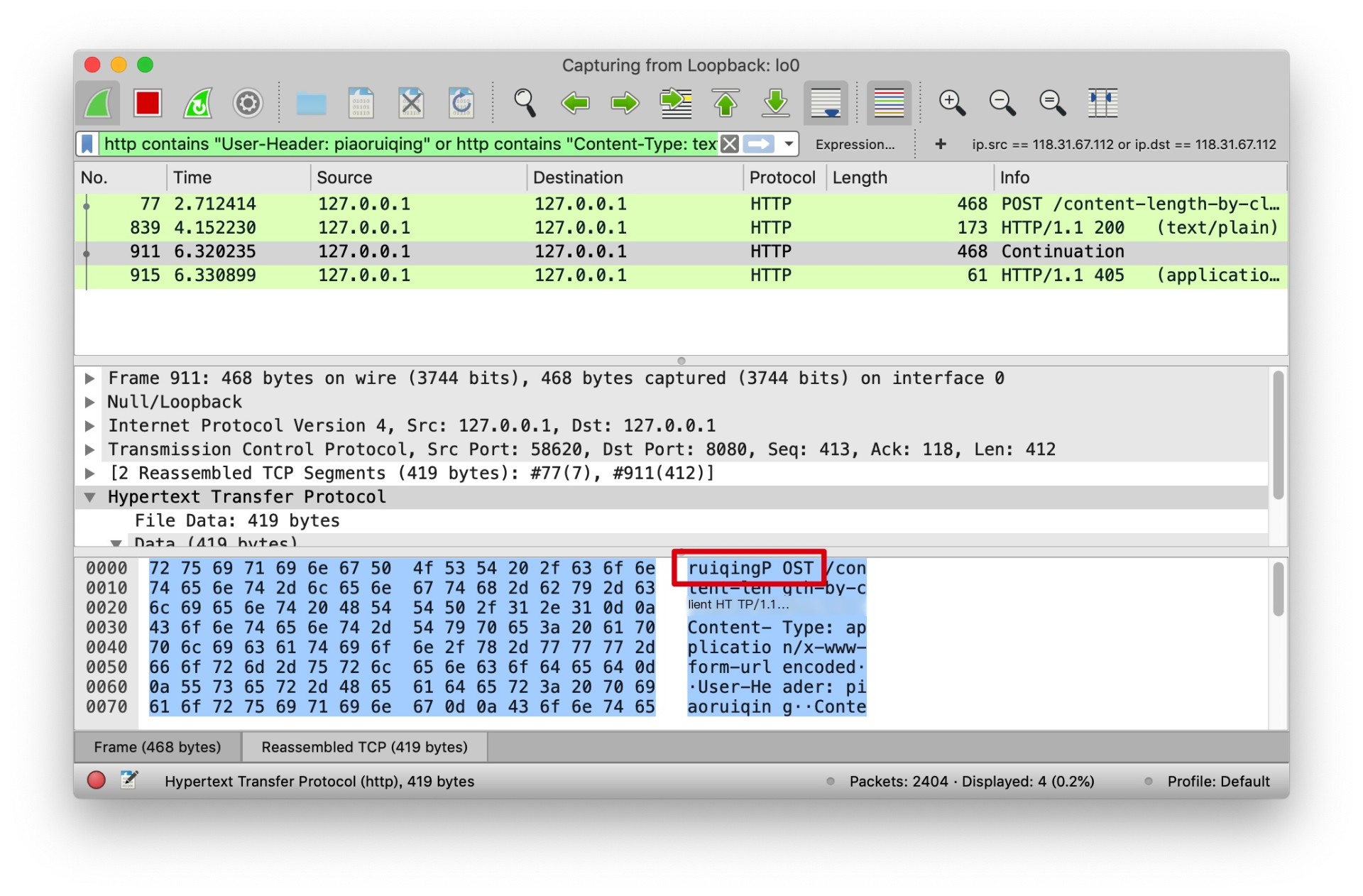
The cause of this situation is that Connection: keep-alive is enabled. If Connection: close is used, the phenomenon produced is each request being truncated, but no parsing confusion occurs (such as concatenating the leftover message from the previous request to subsequent request messages).
Copyright Notice
This article was published on [Piaoruiqing's Blog](https://blog.piaoruiqing.com/), allowing for non-commercial use reproduction. However, reproduction must retain the original author [Piaoruiqing](https://blog.piaoruiqing.com/) and the link: [https://blog.piaoruiqing.com](https://blog.piaoruiqing.com/). For authorization negotiations or cooperation, please contact: [[email protected]](https://blog.piaoruiqing.com/mailto:[email protected]).What to Do If You Can’t Determine the Value of Content-Length
The Content-Length header indicates the byte size of the entity body in the message. However, if the message length cannot be obtained before the request processing is completed, we cannot explicitly specify Content-Length, and instead should use Transfer-Encoding: chunked.
What is Transfer-Encoding: chunked
The data is sent in a series of chunks. The Content-Length header is not sent in this case. At the beginning of each chunk, the current chunk’s length must be explicitly indicated in hexadecimal followed by \r\n, followed by the chunk itself, also ending with \r\n. The terminating block is a regular chunk except for its length being 0.
How Transfer-Encoding: chunked Works
Let’s examine how Transfer-Encoding: chunked works using a file download example. The server code is as follows:
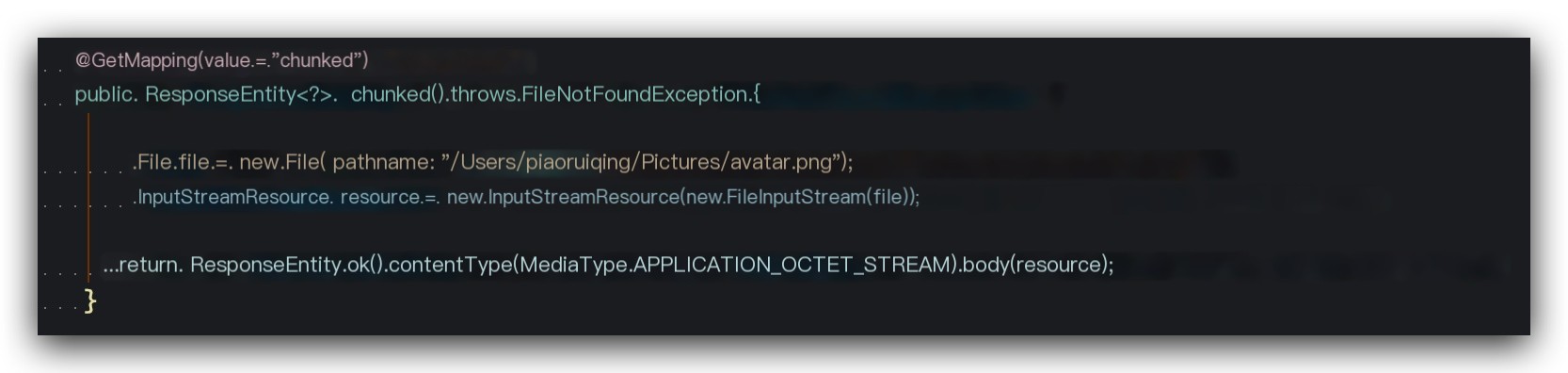
Use postman to initiate a request and observe it with Wireshark, as shown:
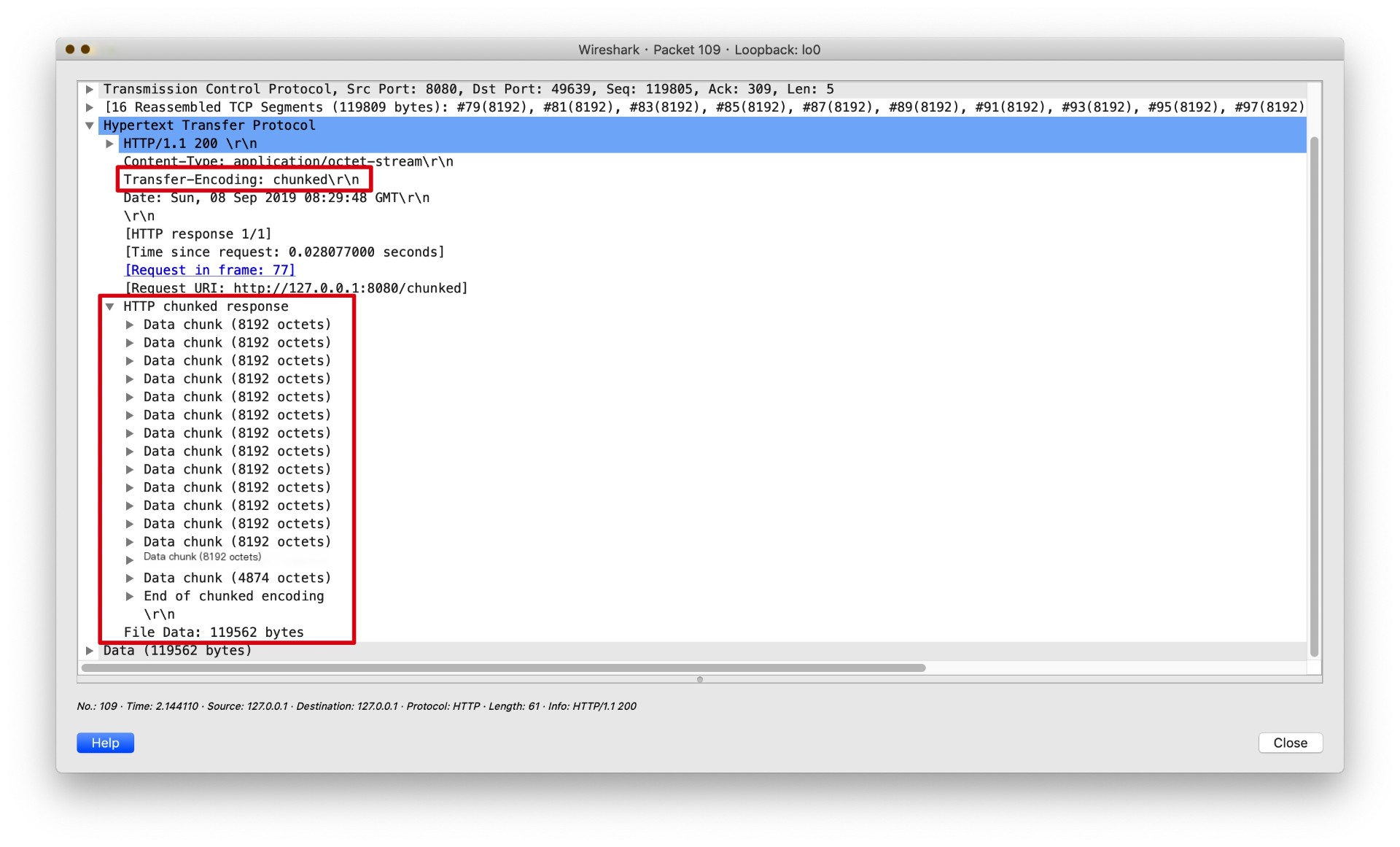
In Wireshark, you can clearly see the chunked data structure, which generally consists of: the returned message is divided into multiple data blocks, each contains two parts, length + data, both parts end with CRLF (\r\n). The terminating block is a special data block with a length of 0, as shown:
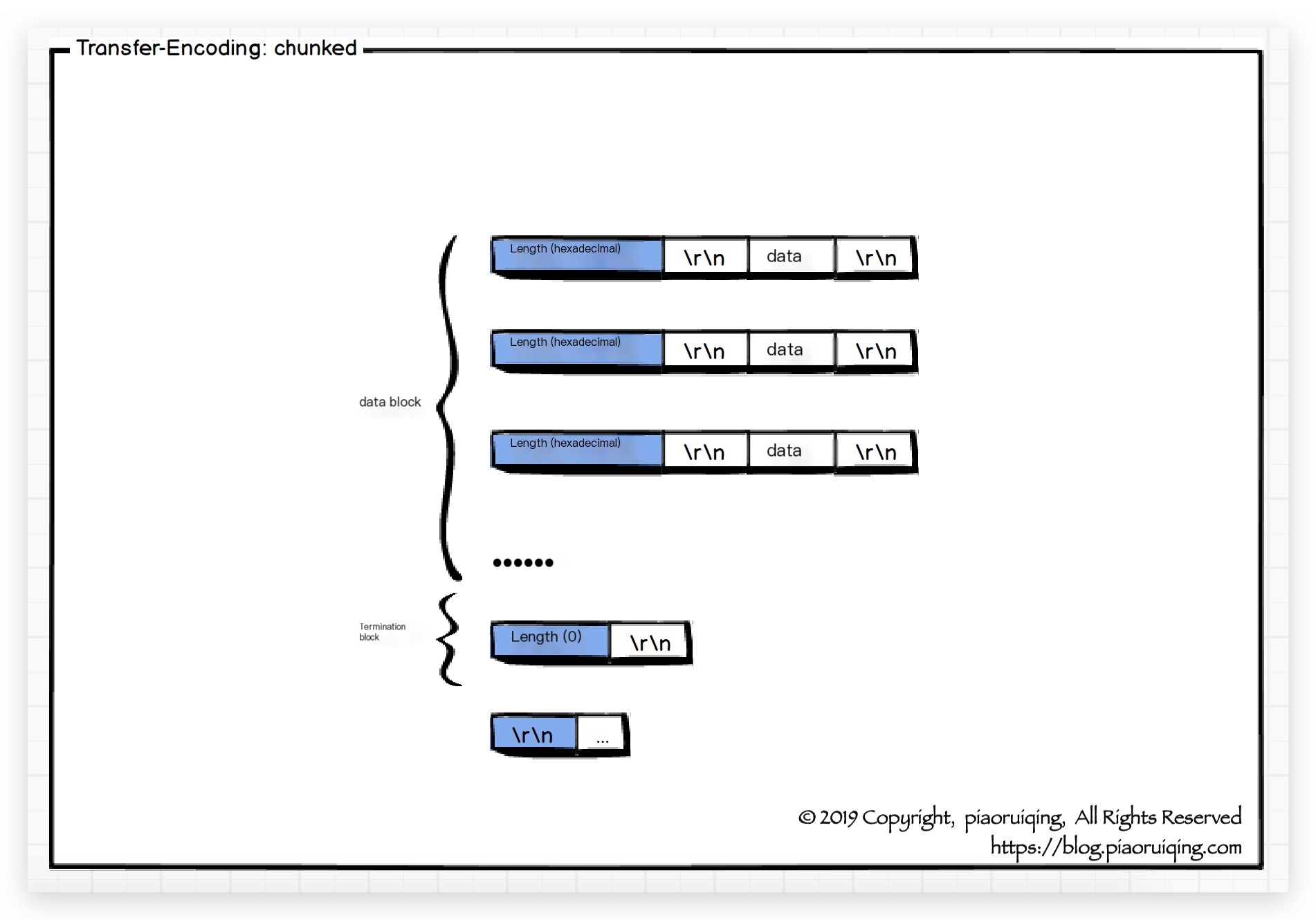
Thus, the chunked encoding is completed. It is mainly used in scenarios where a large amount of data is transferred, but the length of the response is not available until the request is fully processed. For instance, when a large HTML table generated from data queried from a database needs to be transmitted, or when transmitting large amounts of images.
Conclusion
- If
Content-Lengthexists and takes effect, it must be correct, or exceptions will occur. (Greater than the actual value causes timeout, less than the actual value causes truncation and may lead to subsequent data parsing confusion) - If the message contains the
Transfer-Encoding: chunkedheader, thenContent-Lengthwill be ignored.