A security alert on an internal k8s cluster host indicated successful SSH brute force attacks. Upon investigation, it was found that there were abnormal SSH logins on this host for several months, with login records appearing consistently between midnight and 4 AM, and both failed and successful SSH login attempts from the same IP address were interspersed.
It was initially determined that this was an emergency incident not caused by an intrusion. However, how can we pinpoint the cause of abnormal SSH logins in k8s containers?
Identify the Earliest Occurrence of Abnormal Records
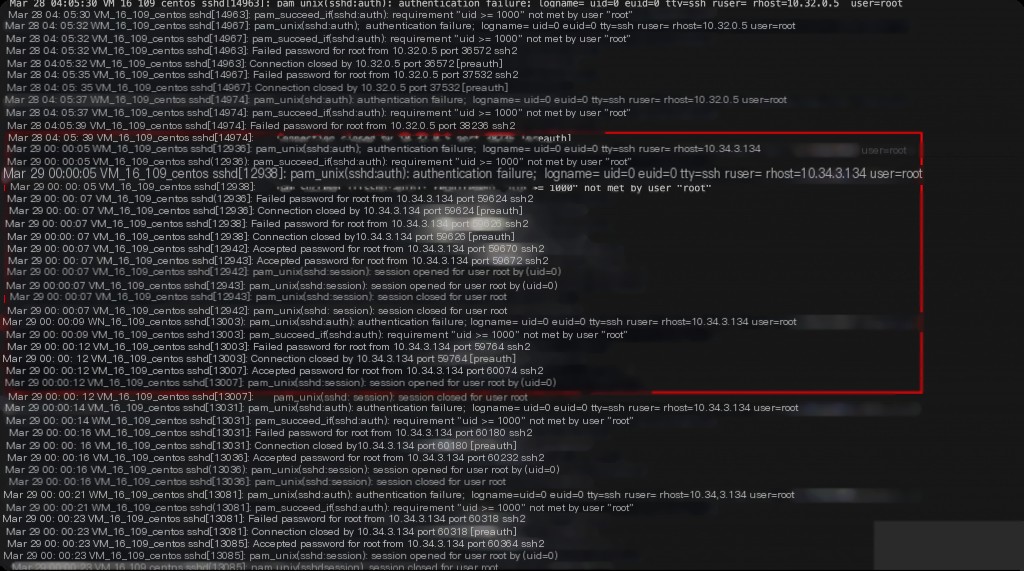
By querying the logs, the earliest record of failed SSH login attempts from an abnormal IP was found, with the first occurrence on March 29th at midnight. The corresponding IP was a node in the k8s cluster, running only container services. Therefore, the investigation direction is from Host –> Container.
Find Newly Created Containers and File Changes at the Corresponding Time
Check for file changes on the k8s host on March 29th.
find / -newermt "2023-03-28" ! -newermt "2023-03-30" -type f -exec ls -lh {} \;
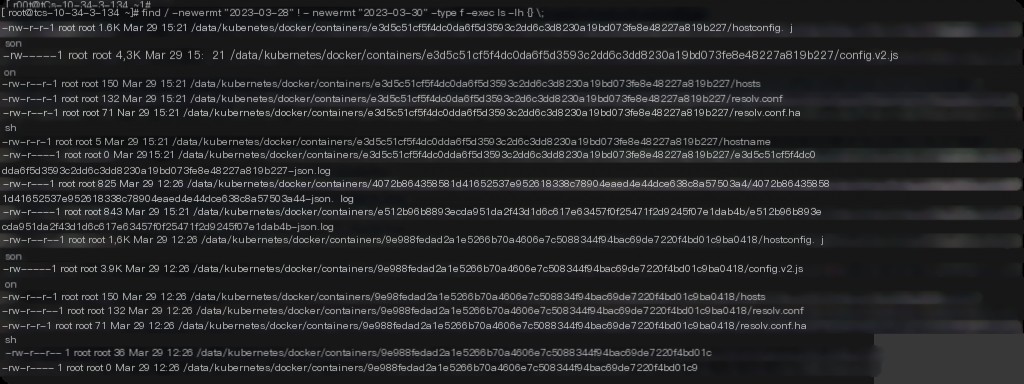
It can be seen that there were indeed file changes, likely caused by newly started container services on March 29th, leading to abnormal SSH logins. Check for containers created on March 29th.
docker ps -a --no-trunc -q | xargs docker inspect --format '{{ .Name }}: Created {{ .Created }}' | grep "2023-03"
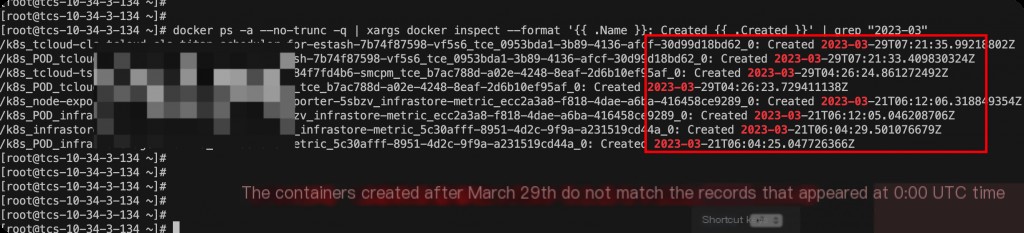
Note that Docker’s time is usually in UTC, and converting to CST requires adding 8 hours.
This does not match the hypothesis, so the anomaly was not caused by newly created containers around March 29th.
Audit Network Requests and Commands with auditd
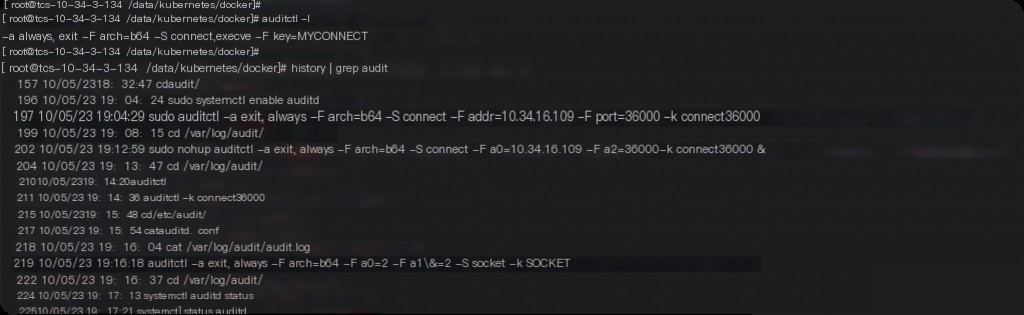
With numerous containers in k8s, a single host runs hundreds of containers, making individual checks inefficient. Since abnormal SSH login records appear consistently at midnight, auditd is directly enabled to audit network requests and commands. The command is as follows:
auditctl -a always,exit -F arch=b64 -S connect,execve -F key=MYCONNECT
Then, wait for the audit results the next day.
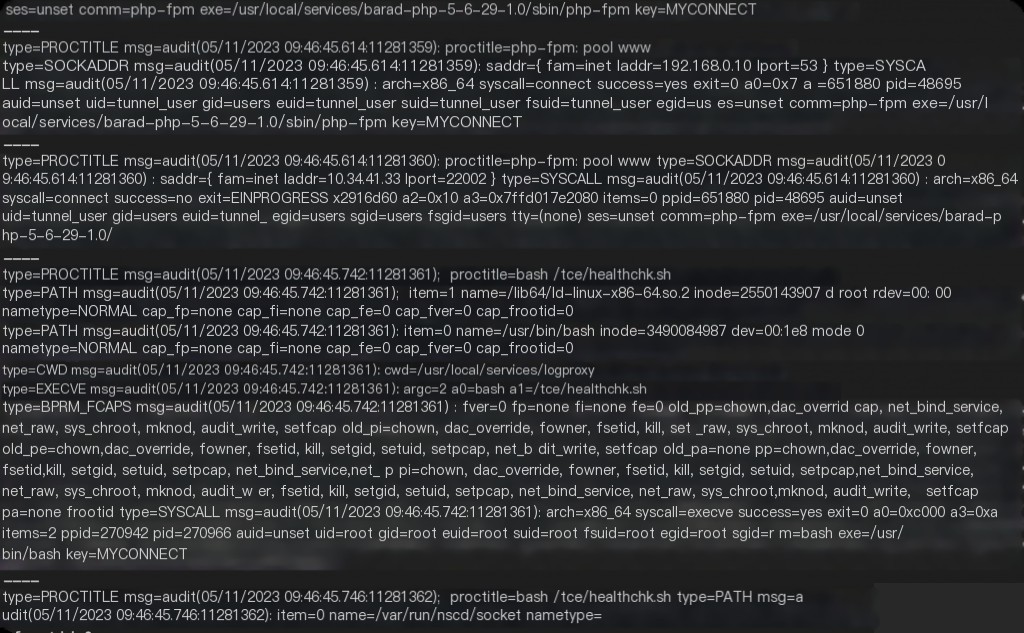
Under normal circumstances, audit should capture the network request process, but no abnormal SSH network request information was found in the audit logs between midnight and 4 AM.
Therefore, it is speculated that there must be an abnormal container exit or a container service crash before midnight.
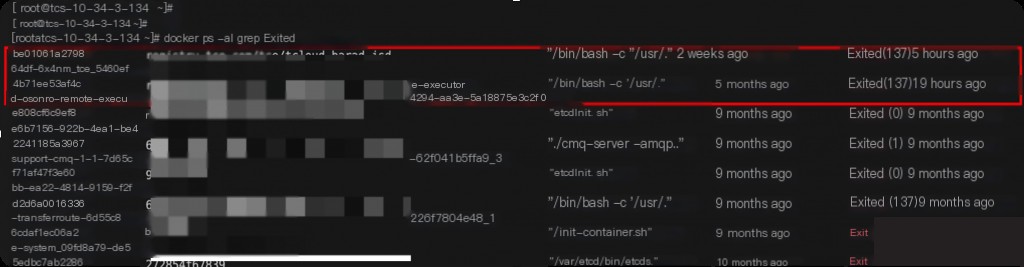
Check all exited containers. From the information of abnormally exited containers, it can be inferred that only the k8s_ocloud-osppro-remote-executor_ocloud-osppro-remote-executor container meets the time requirements.
From the container’s command, it can be determined that it is a remote command execution container. Restart this container and check the container’s log information.
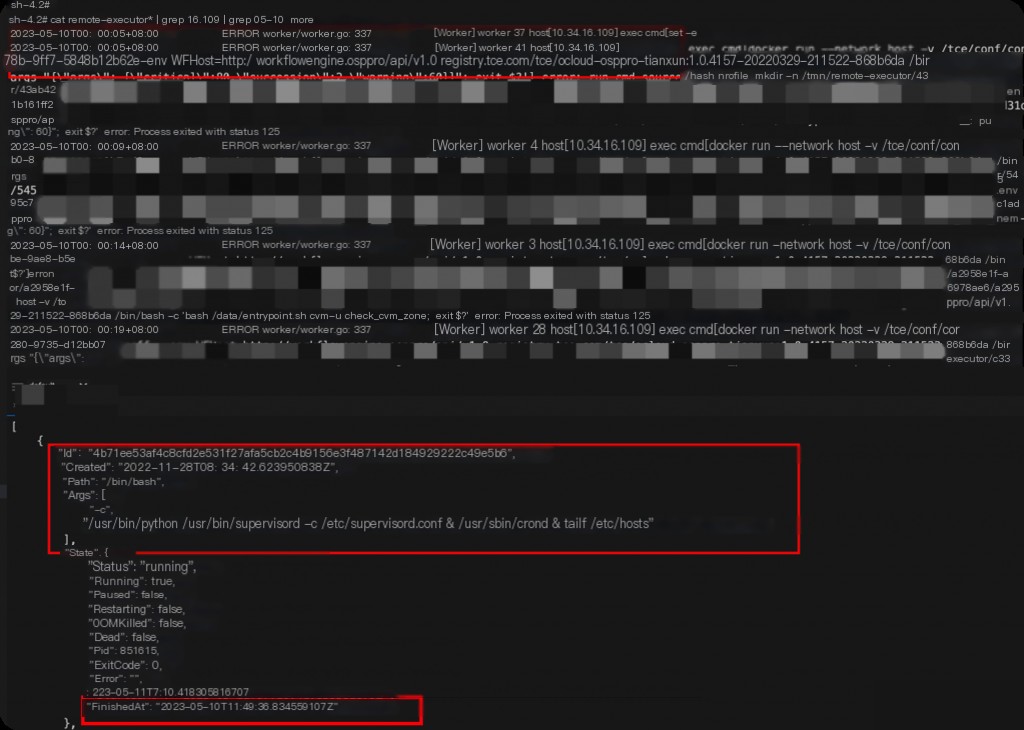
Enter the container to check the server logs, and it was found that the command issuance time matches exactly with the SSH error time and frequency, confirming that the container’s service issuing commands caused the abnormal SSH logins.