Local deployment of the DeepSeek model based on Ollama can be performed by following these steps. Ollama is a tool for running large language models (LLMs) locally, supporting various models, including DeepSeek.

1. Install Ollama
Ollama supports macOS and Linux systems. Here are the installation steps:
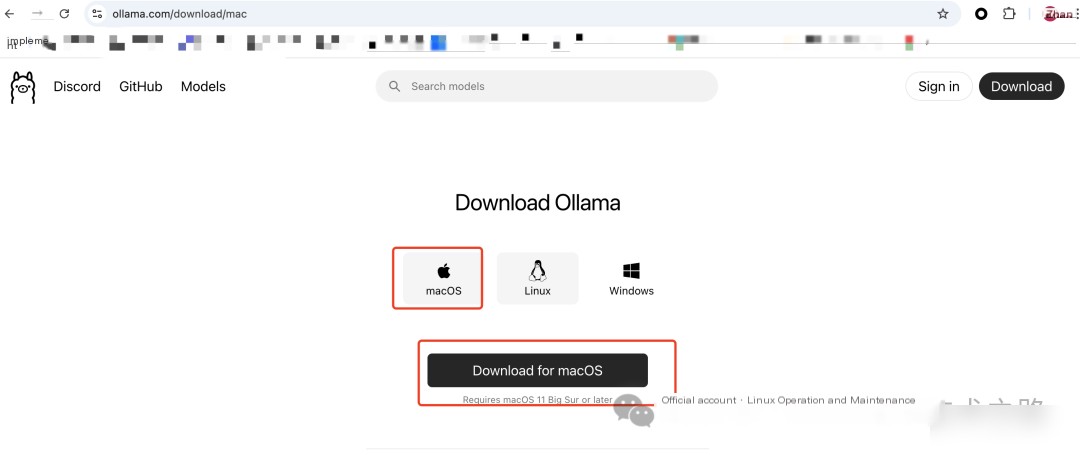
macOS
1. Open Terminal.
2. Run the following command to install Ollama:
brew install ollamaOr download the file (https://ollama.com/download/Ollama-darwin.zip) and install locally

Linux
1. Open Terminal.
2. Run the following command to install Ollama:
curl -fsSL https://ollama.com/install.sh | shWindows DeepSeek model
Ollama currently does not support native Windows, but can be run on Windows through WSL (Windows Subsystem for Linux). After installing WSL, follow the Linux steps.
2. Download DeepSeek Model
Ollama supports loading models from Hugging Face or other sources. Here are the steps to download and load the DeepSeek model:
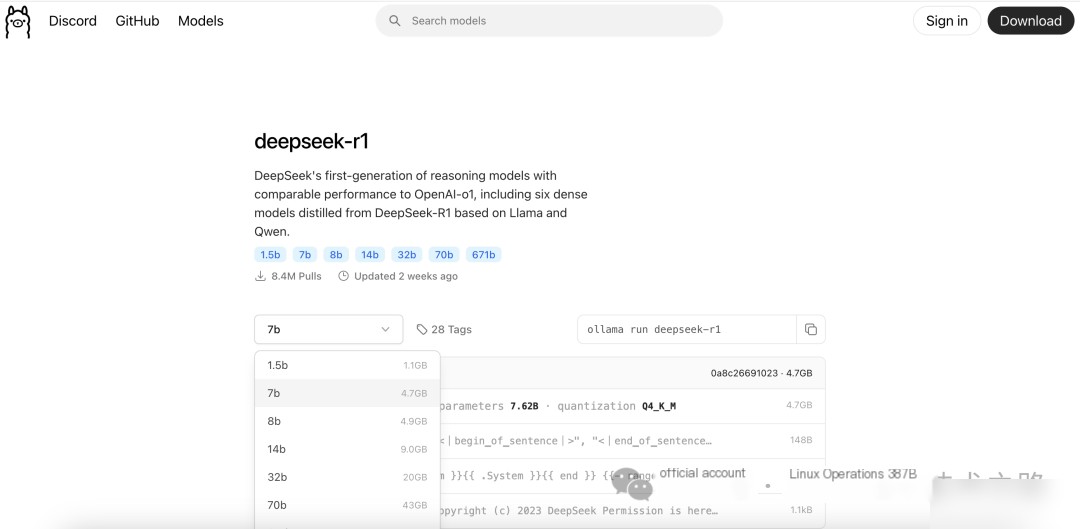
1. Ensure Ollama is installed and running.
2. Use the following command to download the DeepSeek model:
ollama pull deepseek-r1:1.5bIf DeepSeek is not in the default model list, you can manually specify the model file path or URL.
3. Run DeepSeek Model
Once the download is complete, you can run the DeepSeek model using the following command:
ollama run deepseek-r1:1.5bAfter running, Ollama will launch an interactive terminal where you can directly interact with the DeepSeek model.
4. Invoke DeepSeek Model via API
Ollama provides a local API to interact with the model via HTTP requests.
Start API Service
1. Run the following command to start Ollama’s API service:
ollama serveBy default, the API will run at http://localhost:11434.
Send Request
Use curl or programming languages like Python to send requests. Here is an example:
curl http://localhost:11434/api/generate -d '{
"model": "deepseek",
"prompt": "Hello, introduce yourself",
"stream": false
}'Python Example
import requests
url = "http://localhost:11434/api/generate"
data = {
"model": "deepseek",
"prompt": "Hello, introduce yourself",
"stream": False
}
response = requests.post(url, json=data)
print(response.json())5. Performance Optimization
If the model runs slowly, you can try the following optimization methods:
- • Use GPU: Ensure that your system has CUDA or ROCm installed, and configure Ollama to use the GPU.
- • Quantize the model: Quantize the model to lower precision (e.g., 8-bit or 4-bit) to reduce memory usage and improve speed.
- • Adjust parameters: Reduce
max_tokensortemperatureto decrease computation.
6. Troubleshooting
DeepSeek model cannot be downloaded
- • Check your network connection to ensure you can access Hugging Face or the model source.
- • Manually download the model file and specify the path.
Insufficient performance
- • Ensure your hardware meets the requirements (e.g., sufficient memory and GPU).
- • Try to quantize the model or use a smaller model variant.
DeepSeek model API is not accessible
- • Check if the Ollama service is running properly.
- • Ensure that port
11434is not occupied.
7. Graphical Interface
• Use chatboxai: Download https://chatboxai.app/en
• Select model provider: OLLAMA API
• Select model: deepseek-r1:1.5b