

When working to debug network bottlenecks, we typically concentrate on two main factors: latency and throughput (bandwidth). Latency is often simpler to assess by using tools like ping or mtr.
[1]
You can see it at a glance. This article shares a method for debugging throughput.
The scenario that focuses on throughput is generally the so-called Long Fat Networks (LFN, rfc7323
What Are Network Bottlenecks?
For example, when downloading a large file, the throughput does not reach the upper limit of the network. This may be mainly affected by three factors:
a bottleneck on the sending end .
A bottleneck occurred on the receiving end
A bottleneck appears in the middle network layer
The bottleneck on the sending end is usually caused by the buffer not being big enough, because the sending process is that the application calls the syscall, puts the data to be sent into the buffer, and then the system is responsible for sending it out. If the buffer is full, the application will be blocked (if the block API is used) until the buffer is available and then continue to write, producer and consumer mode.
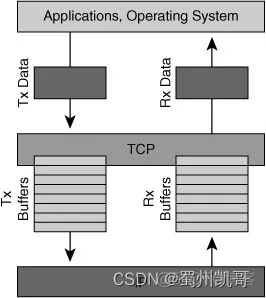
The bottleneck on the sending end is usually easy to troubleshoot, and you can even use the application log to see when the bottleneck occurs. Most of the time, it is the second or third case, which is more difficult to troubleshoot. This happens when the application on the sending end has written the content into the system buffer, but the system does not send it out quickly.
In order to optimize transmission efficiency (note that the transmission efficiency here is not the transmission efficiency of a single TCP connection, but the efficiency of the entire network), TCP will:
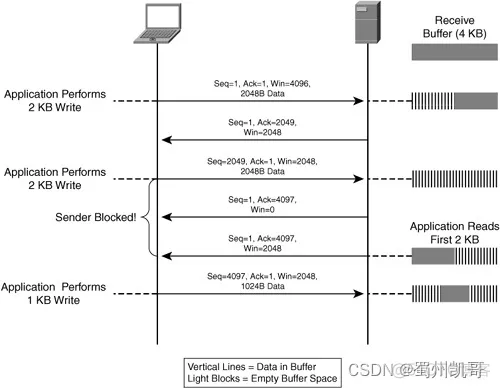
To protect the receiving end, the data sent will not exceed the buffer size of the receiving end (Flow control). The process of sending data to the receiving end is similar to the above. The kernel is responsible for collecting the package and putting it in the buffer, and then the upper-layer application processes the content in the buffer. If the buffer of the receiving end is too small, it is easy to cause a bottleneck, that is, it is filled up before the application has time to process. Then if data continues to be sent, the buffer cannot be stored and the receiving end can only discard it.
Protect the network so that the data sent will not overwhelm the network (Congestion Control). If a bottleneck occurs in the middle of the network, the throughput of the long and fat pipe will be unsatisfactory.
For the protection of the receiving end, when the connection is established between the two sides, the receiving end’s buffer size (receiver window size, rwnd) will be negotiated, and in subsequent transmissions, the receiving end will also report its remaining and accepted window size in each ack reply packet.
In this way, the sender will ensure that it will not send data that exceeds the size of the receiver’s buffer. (This means that the sender is responsible for the total number of unacked messages from the receiver, which will not exceed the receiver’s buffer.)
The principle of network protection is to maintain a window called the congestion window, cwnd. This window is the current network limit, and the sender will not send more than the capacity of this window (the total number of no acks will not exceed cwnd).
How to find the value of this cwnd?
This is the key. The default algorithm is cubic, but there are other algorithms that can be used, such as Google’s BBR.
Debug Network Bottlenecks in Long Fat Networks (LFN)
The main logic is to start slowly, send data for testing, and if the ACK from the receiver is received correctly, it means that the current network can accommodate this throughput. Then, cwnd x 2 is increased, and the test is continued until one of the following situations occurs:
The sent packet did not receive an ACK
cwnd is already equal to rwnd
The second point is easy to understand, which shows that network throughput is not a bottleneck. The bottleneck is that the buffer on the receiving end is not large enough. cwnd cannot exceed rwnd, otherwise it will overload the receiving end.
Regarding the first point, in essence, the sender uses packet loss to detect the network status. If there is no packet loss, it means everything is normal. If packet loss occurs, it means that the network cannot handle the sending speed. At this time, the sender will directly halve cwnd.
However, the actual situation that causes point 1 is not necessarily a network throughput bottleneck, but may be the following situations:
The network has reached a bottleneck
Network quality issues Packet loss
The intermediate network device delayed the delivery of the packet, causing the sender to not receive the ACK within the expected time.
Reasons 2 and 3 will cause cwnd to decrease, and the network throughput cannot be fully utilized.
The above is the basic principle. The following describes how to locate this problem.
rwnd View
The window size is directly in the TCP header, and you can see this field by capturing it.
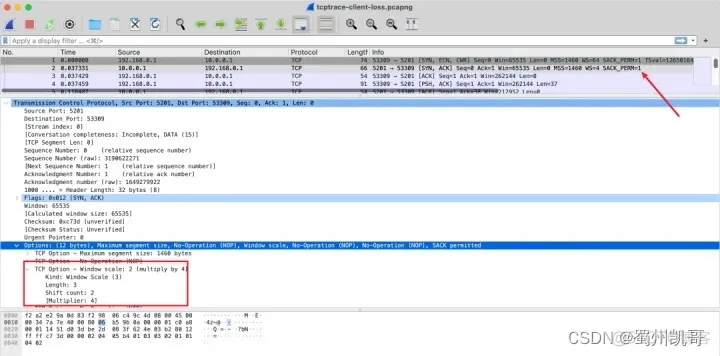
However, the actual window size needs to be multiplied by a factor, which is negotiated during the TCP handshake via TCP Options.
Identifying Throughput Issues: Sender, Receiver, or Network Layer
Therefore, if you want to analyze the window size of a TCP connection, you must capture the packets during the handshake phase, otherwise you will not know the negotiated factor.
cwnd View
Congestion control is a dynamic variable obtained by the sender through an algorithm, which will be adjusted and will not be reflected in the transmission data of the protocol. Therefore, to see this, you must look at it on the sender’s machine.
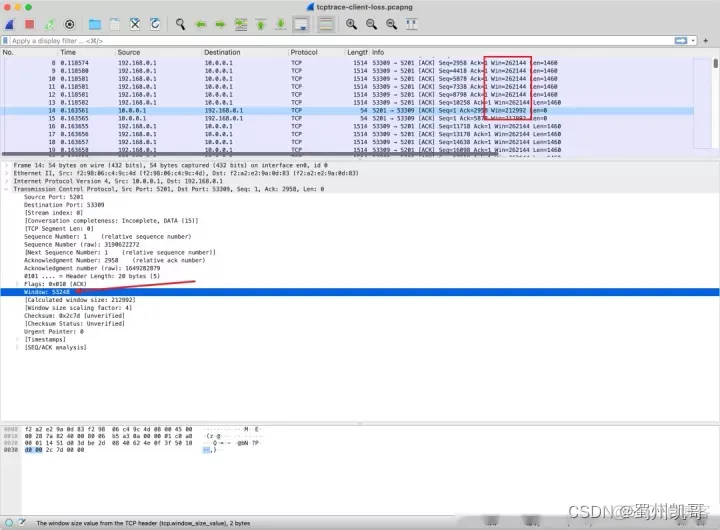
In Linux, you can use the ss -i option to print out the parameters of the TCP connection.
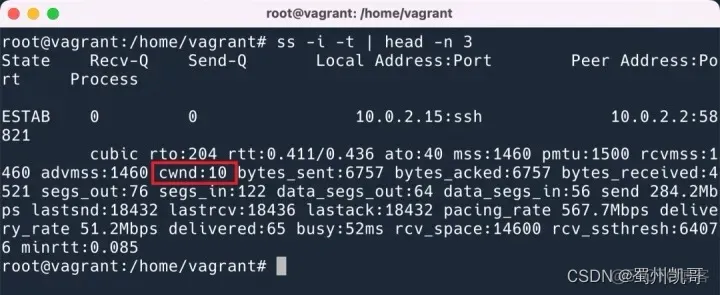
The unit shown here is TCP MSS.
Analyzing TCP Buffers: rwnd and cwnd Explained
The actual size is 1460 bytes * 10.
Wireshark analysis
Wireshark provides a very useful statistical function, which allows you to see at a glance where the current bottleneck occurs. But I didn’t know how to read this graph when I opened it for the first time, and I didn’t find any information on how to read it. Fortunately, my colleague
Yes, he taught me, and I will record it here so that I can teach you too.
First, the way to open it is as follows:
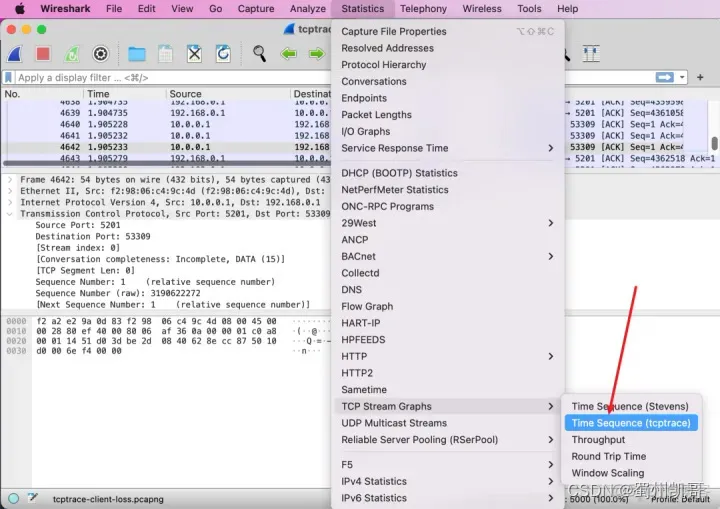
Then you will see the following picture.
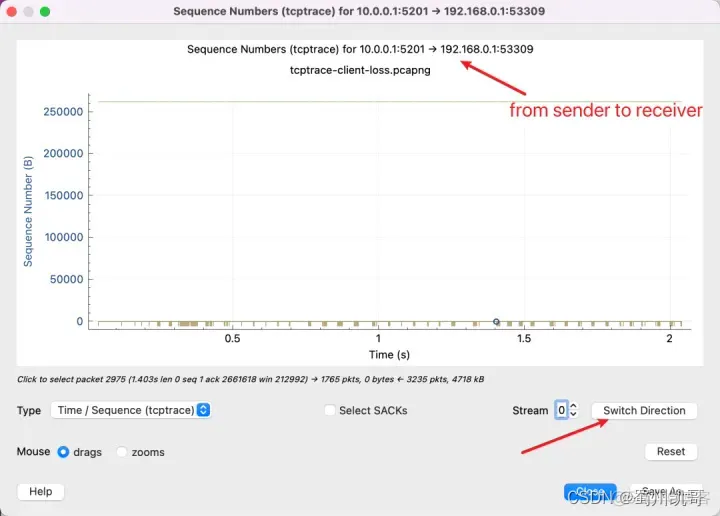
First of all, it should be clear that the tcptrace graph shows unidirectional data transmission, because tcp is a duplex protocol and both sides can send data. The top of the graph says that the data you are currently viewing is sent from 10.0.0.1 to 192.168.0.1, and then press the button in the lower right corner to switch the viewing direction.
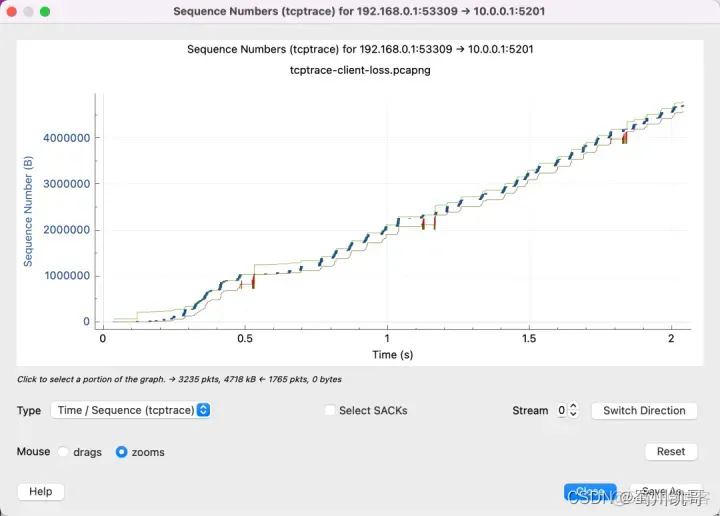
The X-axis represents time, which is easy to understand.
Then understand that the Sequence Number represented by the Y axis is the Sequence Number in the TCP packet. This is very important. All the data in the figure are based on the Sequence Number.
Therefore, if you see the above picture, it means you read it the wrong way, because the Sequence Number of the data has not increased, which means that almost no data has been sent. You need to click Switch Direction.
That’s right, you can see that the Sequence Number we transmit increases as time goes by.
There are 3 lines here, with the following meanings:
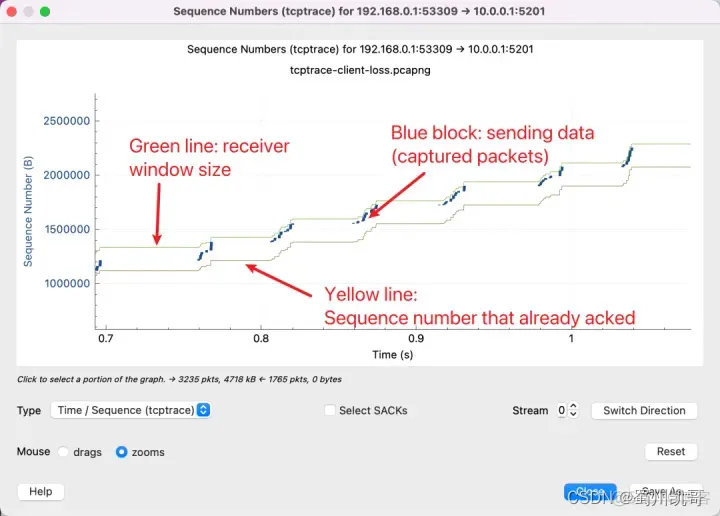
In addition, there are two other lines:
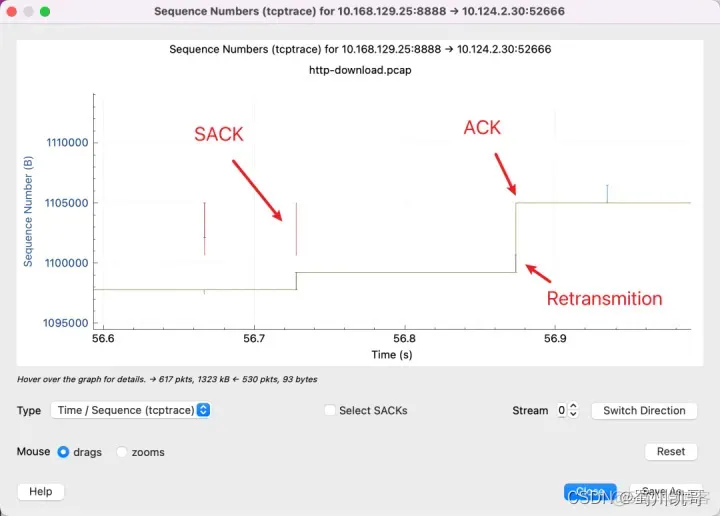
What you need to remember is that the Y axis is the sequence number. The red line indicates that the SACK line indicates that I have received this sequence number. The yellow line indicates the ACKed sequence number. Then the sender will know that the packet was lost in the gap in the middle. The vertical gap between the red and yellow lines is the packet that has not been ACKed. Therefore, it needs to be retransmitted. The blue line indicates that it has been retransmitted again.
After learning to read these pictures, we can recognize several common patterns:
Packet loss
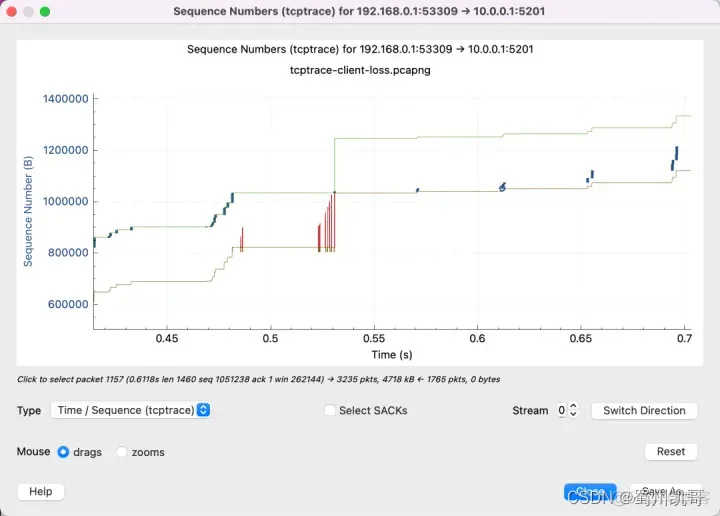
A lot of red SACKs indicate that the receiving end is repeatedly saying: There is a packet in the middle that I did not receive, there is a packet in the middle that I did not receive.
Throughput is limited by the receive window size
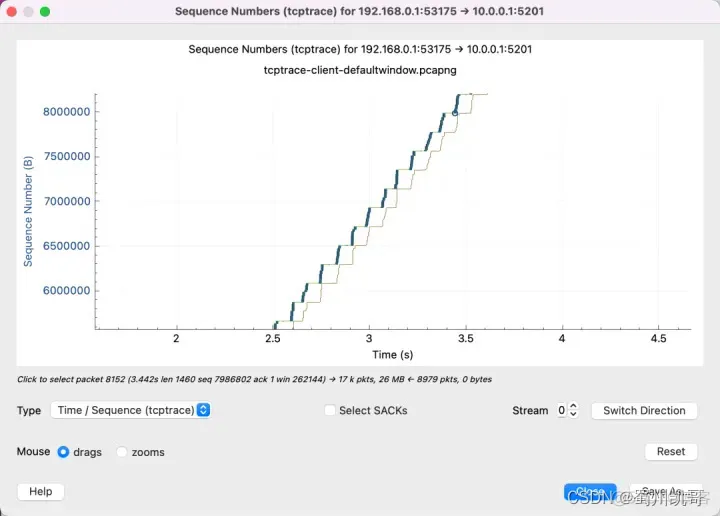
From this graph, we can see that as the yellow line (ACK at the receiving end) rises, the blue line will also rise (the sending end starts sending) until it fills up the green line (window size). This means that the network is not a bottleneck and the buffer size at the receiving end can be increased.
Throughput is limited by network quality
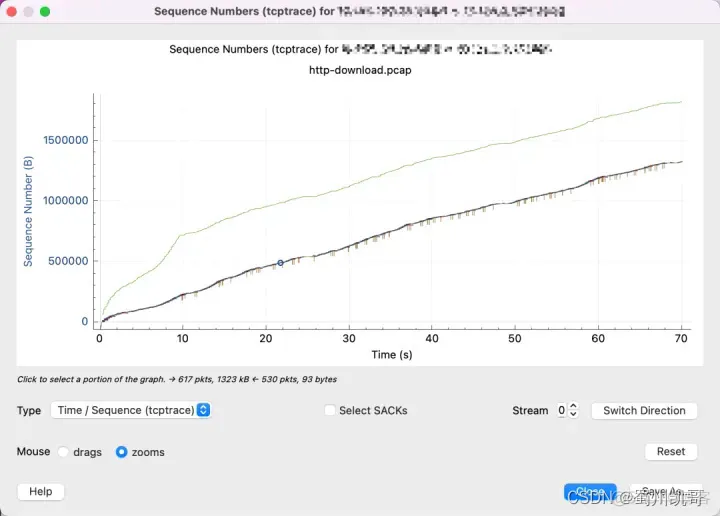
As can be seen from this figure, the window size on the receiving end is far from being a bottleneck, and there is still a lot of room.
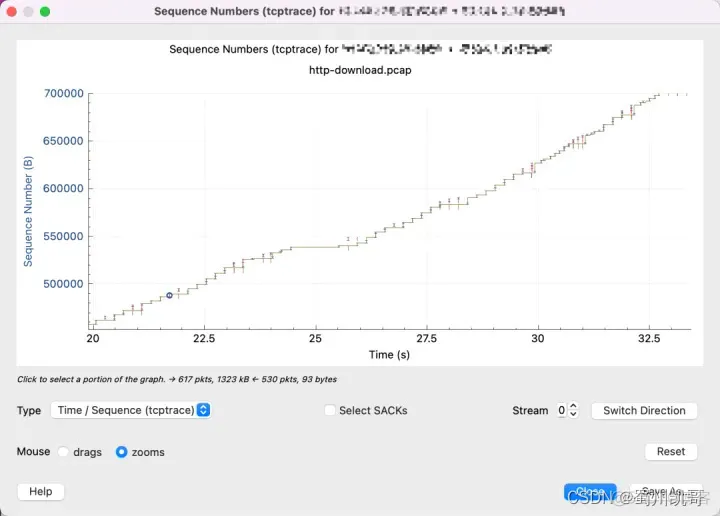
Zooming in, we can see that there are a lot of packet losses and retransmissions, and only a little data is sent each time. This means that cwnd is probably too small and is limited by the congestion control algorithm.
Summary
This article explores effective techniques to debug network bottlenecks, specifically focusing on latency and throughput. While latency can be assessed using simple tools like ping or mtr, tackling throughput, especially in Long Fat Networks (LFNs), demands a comprehensive strategy. Throughput problems typically arise from bottlenecks at the sending end, receiving end, or within the network infrastructure. The article discusses how a bottleneck at the sending end often results from insufficient buffer capacity, where the application queues data until the system has bandwidth to transmit it. TCP’s flow control ensures the data does not exceed the receiver’s buffer size, while congestion control, managed via the congestion window (cwnd), helps to avoid overwhelming the network. For troubleshooting, the article highlights essential tools and techniques to address these bottlenecks, including analyzing the receiver window size (rwnd) and congestion window through sender logs. It demonstrates using diagnostic tools like Wireshark to visualize network data patterns effectively. Recognizing patterns such as packet loss and throughput constraints is key to enhancing network troubleshooting. This overview integrates crucial concepts like buffer limitations, flow control, and congestion control to optimize network transmission efficiency, while also emphasizing practical troubleshooting tools and methods to overcome bottlenecks. Key terms include Debug network bottlenecks, TCP, flow control, congestion window, and Wireshark.