

Yu Yuxiang, who graduated with a master’s degree in 2017, works at Tencent TEG Basic Infrastructure Financial Business Group, focusing on server back-end development. Currently, Yu is involved in developing the cloud payment project launched by Tencent Cloud and WeChat Pay, utilizing HTTP/2 features.
Introduction
The main design ideas of HTTP/2 are primarily derived from Google’s SPDY protocol. A standardized version of SPDY by the Internet Engineering Task Force (IETF) eventually resulted in HTTP/2. Let’s delve directly into the new features of HTTP/2 and compare them with HTTP/1.x.
I. Single Long-Standing Multiplexed Connection
1. Single Long-Standing Connection
In HTTP/2, when a client requests a page from a server of a specific domain, only one TCP connection will be established, even if the page contains hundreds of resources. Previously, HTTP/1.x would typically create 6-8 TCP connections to request these over a hundred resources. A single connection is a main advantage of HTTP2, as it reduces the latency caused by TCP handshakes (especially if SSL/TLS is involved, HTTP2 can eliminate many unnecessary SSL handshakes, as everyone knows SSL handshake is slow).
We also know that the TCP protocol has a sliding window and slow start mechanism, meaning after establishing a new connection, data is initially transmitted slowly, then as the sliding window expands, it can be sent at higher speeds. In this case, as the sliding window of this connection just expands, HTTP1.x creates a new connection to transmit data (it’s like HTTP2 is driving smoothly on the highway while HTTP1.x is like a bus that stops and goes intermittently). Due to this reason, the inherently bursty and short-term HTTP connection becomes very inefficient.
Hence, in HTTP2, using a single long-standing connection avoids the network overhead of creating multiple TCP connections, improving throughput.
2. Multiplexing
How can it be both a single connection and multiplexing? Backend developers should be familiar with multiplexing, for example using select, poll, epoll to manage a bunch of fds. Here, although HTTP2 only has one TCP connection, it is logically divided into many streams. This feature is quite crucial. Let’s look at the diagram borrowed from the internet below.
 >
>
Image source: http://www.360doc.com/content/16/0120/09/30136251_529253725.shtml
How did http1.x do it before? On a single TCP connection, multiple requests could only be executed serially! Given our current network bandwidth is so large, isn’t this wasteful? Unlike HTTP2, regardless of how many requests there are, as long as they’re present, they can be thrown into the connection, which can significantly reduce the loading time of a page.
How does HTTP2 achieve multiplexing? Let’s use an analogy: consider a highway, the road is singular, but aren’t there multiple toll gates?
HTTP2 splits the information to be transmitted into binary frames, with header information encapsulated into HEADER Frames, and the corresponding request body placed into DATA Frames. A frame can be viewed as a car on the road, as long as these cars are numbered, let car 1 exit from gate 1, and car 2 from gate 2, differentiating different HTTP requests or responses. However, it is required that frames of the same request or response must maintain order (FIFO), although frames of different requests or responses can be interleaved. This is HTTP2 multiplexing, ensuring that network bandwidth is fully utilized and concurrency is improved.
Further, HTTP2 can assign priority to these streams (lanes) which can be dynamically altered, for instance setting CSS and JavaScript files to have higher priority than images, allowing code files to download faster and execute sooner.
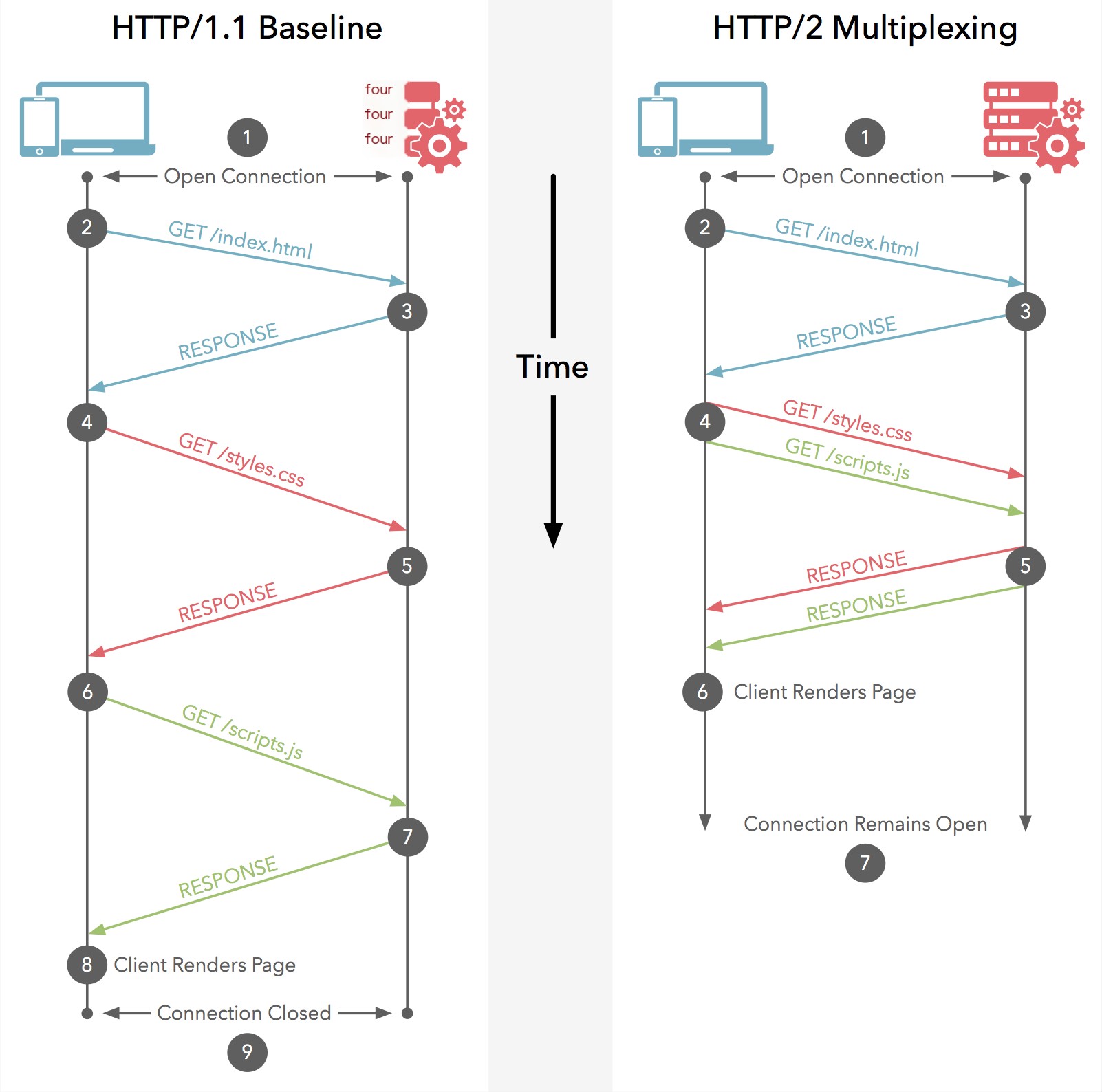
Looking back, when requesting a page containing dozens or hundreds of resources, the process differences between HTTP1.x and HTTP2 are shown in the following diagram:
 >
>
I guess even those not proficient in English can understand, here http1.x established 6 to 8 TCP connections and executed each request serially with these connections, while HTTP2 can simultaneously send all requests, even compressed, making the superiority obvious.
II. Header Compression and Binary Format
http1.x has always been plain text, which I can only think of as advantageous for readability and debugging. But now many things use HTTPS, and SSL turns plain text into binary, negating that advantage.
Hence, HTTP2 adopted HPACK compression to compress headers, reducing message size (to debug such protocols requires tools like curl, and to further analyze network data streams requires HTTP2 parsers like Wireshark). HPACK converts common field names and values in messages into an index, essentially maintaining a static index table, for example, converting method: GET to a value with index 2 in the index table. However, some uncertain things like the browser’s user-agent need dynamic indexing.
Therefore, it also maintains a dynamic index table, with static table index values ranging from 2 to 61. If during data transmission a user-agent Mozilla/5.0 is encountered, it is appended at the 62nd index of the dynamic index table, from then on, replaced by 62. This dynamic index table is gradually built during data transmission, while the static index table is fixed.
Moreover, for entirely uncertain resource paths, HPACK uses Huffman coding for compression, significantly reducing header content. Here’s an illustrative diagram of HPACK:
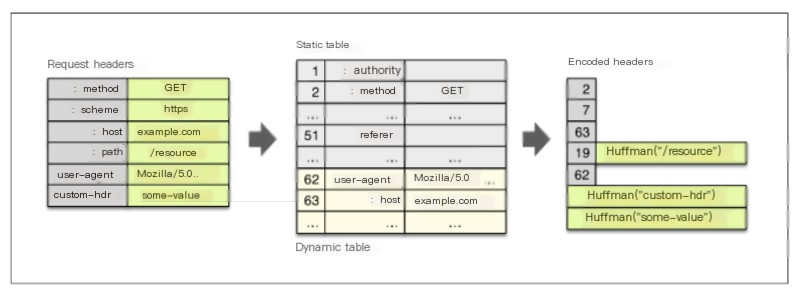
Why compress headers?
Because some repetitive items are present in every HTTP request, such as method: GET. When a client requests several resources (like images on a page) from the same server, these requests appear almost identical. Thus, many such consistent items are perfect candidates for compression.
Additionally, the size of HTTP 1.1 requests has become increasingly large, sometimes even exceeding the initial TCP window size, severely slowing down the request sending speed. As they must wait for a response with ACK before proceeding. Especially when the HTTP request content surpasses the maximum TCP segment size, it is split into multiple TCP segments, and compressing can reduce TCP segment count, cutting down several RTT times.
Conversely, header compression introduces CPU consumption, and if the header fits into a single TCP segment, compression is essentially redundant. Moreover, the body of most response messages is generally much larger than the header, rendering header compression somewhat superfluous.
III. Server Push
This feature is commonly referred to as “cache push.” The main idea is: when a client requests resource X, and the server knows it will likely need resource Z too, the server can actively push resource Z to the client before it sends the request.
This feature assists the client in caching Z for future use. Server push requires clients to explicitly allow servers to provide this functionality. Yet, clients can still decide whether to interrupt the push stream. If unnecessary, clients can abort by sending a RST_STREAM frame.
The above are the main new features of HTTP (though there are many more, which we won’t discuss in detail here). Finally, a quick plug for HTTP2 + SSL: it seems currently browsers only use the HTTP2 protocol when the server supports HTTP2 and uses SSL. To summarize, why can HTTP2 eliminate SSL overhead in HTTP1.x?
1. Single long-standing connection reduces SSL handshake overhead
2. Compressed headers reduce data transmission size
3. Multiplexing significantly increases transmission efficiency, eliminating the need to wait for a prior request’s response
4. Unlike http1.x, which combined multiple files or resources into one to optimize, caching becomes easier to hit (how would you cache a combined entity in http1.x?)
Wow, writing an article is truly exhausting. But if I have time, I’ll write about how to deploy HTTP2 on nginx and conduct some experiments to test HTTP2 performance.