During an emergency inspection, a self-check notice from the cybersecurity team was received. The xxx system was accessed by a foreign organization on a certain day, with a communication traffic of xxMb.
Analysis Approach
- The accessed IP is highly likely to be foreign.
- Communication traffic is xxMb.
Since all traffic of this system goes through the WAF, we can compare the size of response packets from all foreign IP requests in the logs of that day.
WAF Log Analysis
{"accept":"application/json, text/javascript, */*; q=0.01","appid":1253288859,"body":"","bot_action":"","bot_ai":0,"bot_id":"","bot_label":"","bot_module":"","bot_rule_id":"","bot_rule_name":"","bot_score":0,"bot_stat":0,"bot_ti_tags":"","bot_token":"","bytes_sent":397,"client":"145.224.95.55","connection":"keep-alive","content_type":"-","cookie":"xxxxxxxxx","domain":"xxxxxx.cn","edition":"sparta-waf","encoding":"gzip, deflate","headers":"","host":"xxxxxx","instance":"waf_00000047i","ipinfo_city":"Kyiv","ipinfo_detail":"Space Exploration Technologies Corporation","ipinfo_dimensionality":39.89489,"ipinfo_isp":"Space Exploration Technologies Corporation","ipinfo_longitude":-2.98831,"ipinfo_nation":"Ukraine","ipinfo_province":"Kyiv","ipinfo_state":"ES","language":"zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7","method":"GET","msec":1715097564747,"query":"method=initSea330199\u0026requestid=26148343","referer":"http:///spa/workflow/static4mobileform/index.html?_random=1715097543877","request_length":1271,"request_time":0.089,"schema":"http","status":200,"time":"07/May/2024:23:59:24 +0800","timestamp":"2024-05-07T23:59:24+08:00","ua_crawlername":"","ua_fake":0,"ua_goodbot":0,"ua_type":"","upstream":"140.143.159.33:80","upstream_connect_time":0.007,"upstream_response_time":0.082,"upstream_status":200,"url":"/mxxxxxxxxxxxx.jsp","user_agent":"Mozilla/5.0 (Linux; Android 12; ANA-AN00 Build/HUAWEIANA-AN00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/109.0.5414.86 MQQBrowser/6.2 TBS/046805 Mobile Safari/537.36 wxwork/3.0.31000 wxworklocal/3.0.31000 wwlocal/3.0.31000 wxwork/3.0.0 appname/wxworklocal-customized MicroMessenger/7.0.1 appScheme/wxworklocalcustomized Language/zh_CN","uuid":"e46f790def349c22d11f863d86c1da54-633e7ff9d32dcb8bdc2c5ce6fcfb7c89","x_forwarded_for":"-"}
Above is the raw access log from Tencent Cloud WAF, with each line representing a request.
Here, client is the source IP of the request, and bytes_sent is the response size, including the response header, in bytes, representing the downstream bandwidth. We need to focus on these two fields.
Extracting Each IP’s Requests to a Separate File
cat waf_access.json | jq -r ".client" | sort -u | xargs -n1 -P 7 sh -c 'grep $1 waf_access.json > $1.txt' _
The above command allows us to extract all IP access requests into their respective files at once.
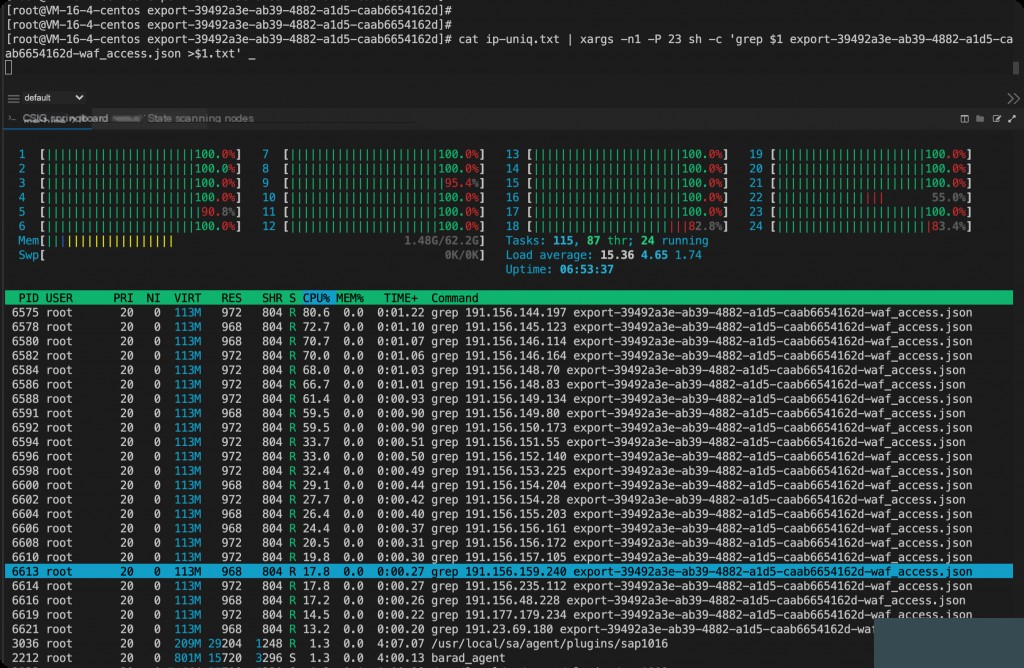
However, this approach is very inefficient, as the repeated matching consumes a lot of CPU resources and time.
This way, each IP’s requests are categorized into their respective files.
Command Optimization
Although the above command works, it is not elegant, as it matches each IP in the file again. The best solution is to perform the search only once and achieve the effect of storing while searching.
cat waf_access.json | jq -c '. | {client: .client, record: .}' | \
while IFS= read -r line; do
client=$(echo "$line" | jq -r '.client')
record=$(echo "$line" | jq -c '.record')
echo "$record" >> "${client}.txt"
done
- Use
jqto extract theclientfield and the entire record from each entry, compressing it into a single-line JSON format. - Iterate through each line, extracting the
clientfield and the corresponding record. - Append the record to the file corresponding to the
clientfield value.
This method is much more efficient than multiple grep commands, as it only traverses the JSON file once. However, this approach is implemented in a single process, so the overall speed is still a bit slow.
It can also be implemented in a multi-process manner.
cat waf_access.json | xargs -n1 -d '\n' -P 20 sh -c 'client=$(echo $1 | jq -r .client) && echo $1 >> "$client".txt ' _
However, starting a new process for each line to match and write to a file is inefficient and slower.
File Splitting for Parallel Processing
# Step 1: Split the JSON file into 20 smaller files
split -n l/20 -d --additional-suffix=.json waf_access.json split_
# Process 20 files in parallel
ls split_*.json | xargs -n1 -P20 sh -c 'cat $1 | while IFS= read -r line; do client=$(echo "$line" | jq -r '.client'); echo "$line" >> "${client}.txt"; done' _
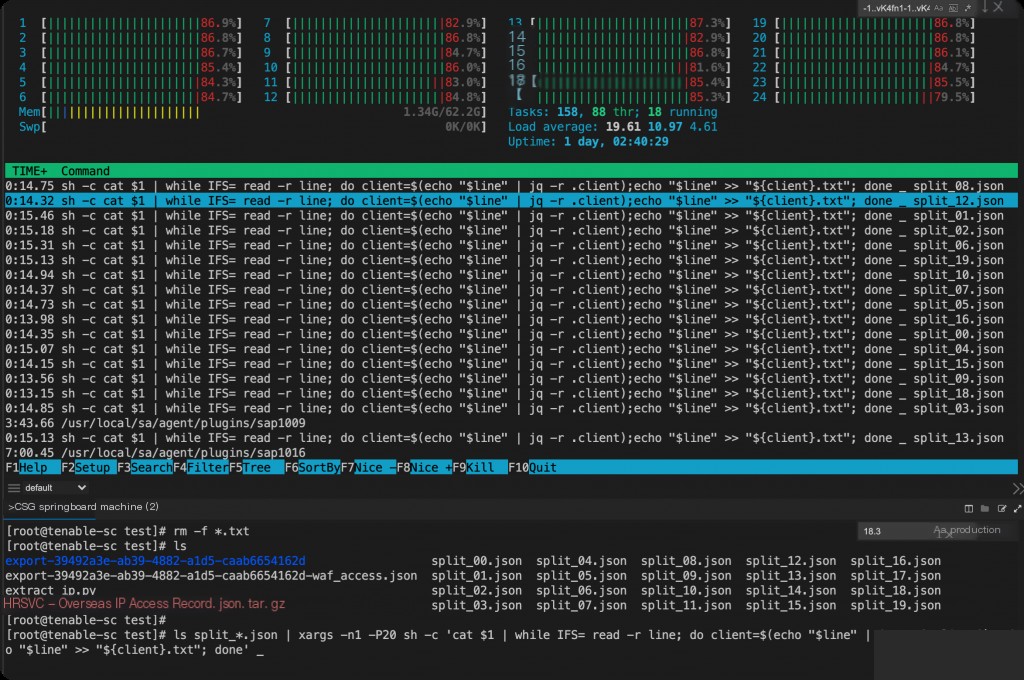
But the actual operation is still very slow. It is unclear whether jq itself is inefficient?
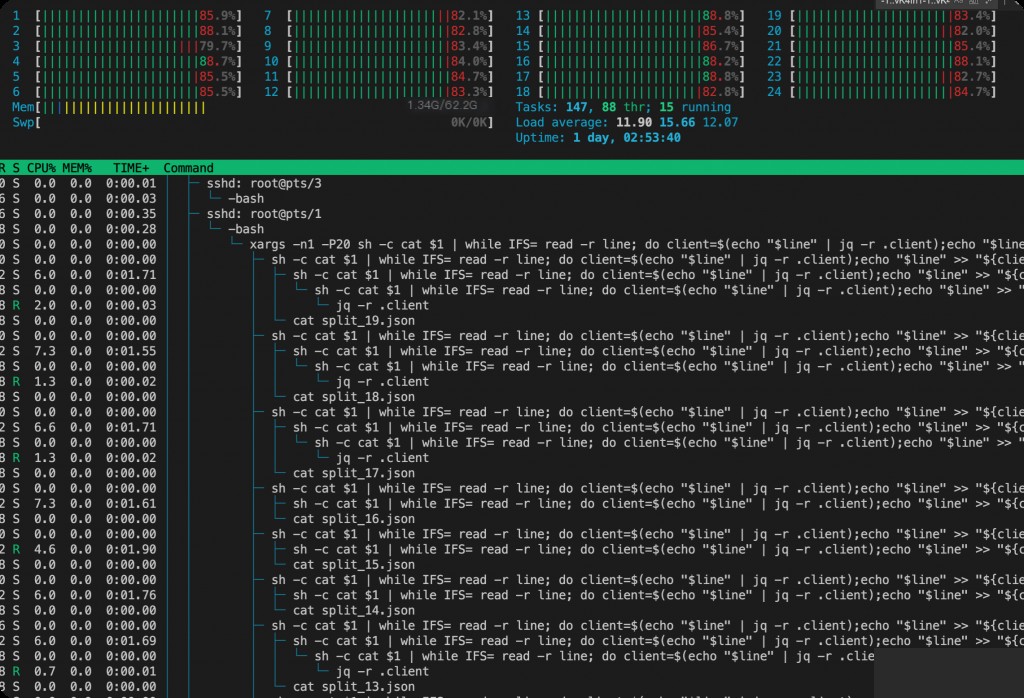
Analysis of the process chain reveals that each jq command generates a new process to handle it, wasting CPU on context switching, naturally leading to low efficiency.
Python Code Implementation
python
import json
from collections import defaultdict
# Open the log file
with open(‘waf_access.json’, ‘r’) as f:
# Read all lines
lines = f.readlines()
# Use a default dictionary to store requests for each IP
ip_requests = defaultdict(list)
# Process each line
for line in lines:
try:
# Parse JSON data
data = json.loads(line)
# Get the IP address
ip = data[‘client’]
# Add the line data to the corresponding IP’s list
ip_requests[ip].append(line)
except json.JSONDecodeError:
# Skip lines that cannot be parsed
continue
# Write each IP’s requests to a separate file
for ip, requests in ip_requests.items():
with open(f'{ip}.txt’, ‘w’) as f:
f.writelines(requests)
print(“Completed extracting requests for all IPs.”)
Here is the approach provided by ChatGPT, which cleverly uses a dictionary to solve the problem of matching IPs multiple times.
After testing, the Python script is the most efficient, taking only a few seconds on a single core, while the shell command running on 24 cores takes 10 minutes.
Why use collections.defaultdict instead of dict?
The main reason for using collections.defaultdict instead of a regular dict is that it automatically creates a default value for each new key. This eliminates the need to manually check if a key exists before adding it to the dictionary, simplifying the code and avoiding errors.
In this specific example, we need to store a list of requests for each IP address. By using defaultdict, we can directly append requests to each IP address without checking if the IP address already exists in the dictionary.
Calculating the total response packet size for each IP
sh
ls *.txt | xargs -n1 -P24 -I {} sh -c ‘jq -r .bytes_sent {} | awk -v filename=”{}” “{ sum += \$1 } END { printf \”%s total: %.2f MB\n\”, filename, sum / (1024 * 1024) }”‘
-P 24 runs 24 processes simultaneously, maximizing CPU usage.
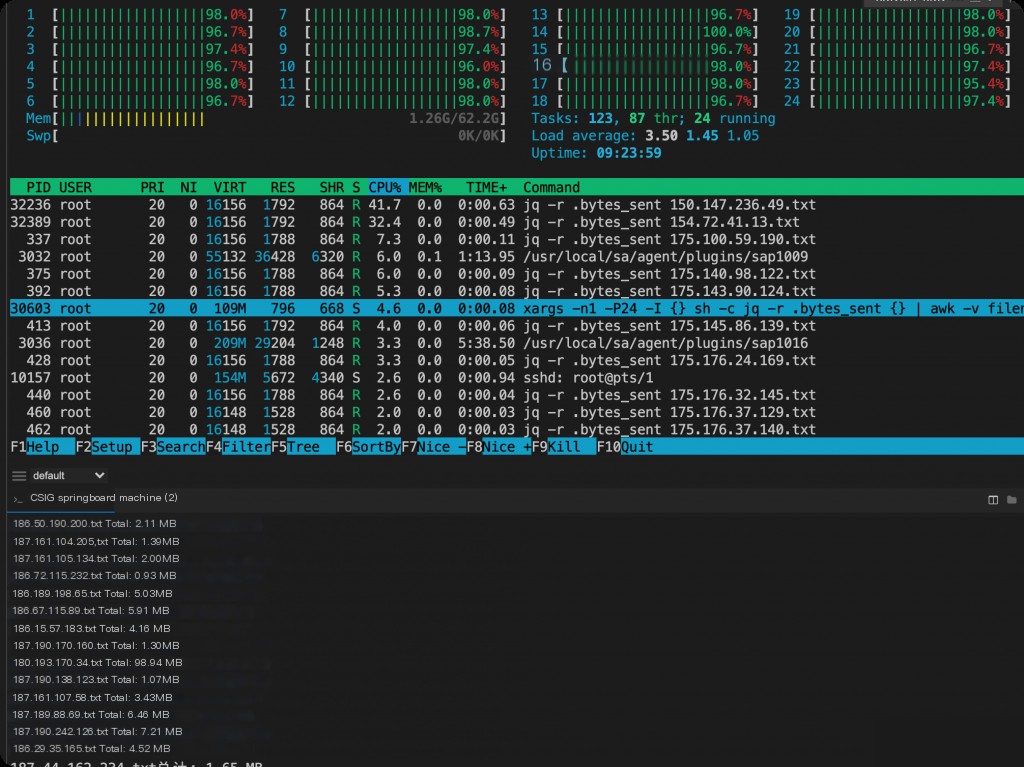
All IP traffic sizes are calculated. By comparing with the announced traffic, you can identify which IP’s communication traffic meets the criteria.
Similarly, Nginx logs can also be calculated using this method.